
Engineering teams need agents that stay reliable across hours of tool use, not clever single turns. Claude Sonnet 4.5 targets that gap with sustained 30+ hours of autonomous work and leading results on SWE-bench Verified and OSWorld, signaling stronger computer use and repo-grounded edits.
The release pairs model gains with the Claude Agent SDK, checkpoints, memory tools, and permissioning to keep progress safe and auditable.
This guide explains why those primitives matter, how to validate them on your stack, and where Sonnet 4.5 fits against peers. Bottom line: ship long-horizon coding agents, but validate locally with guardrails and metrics.
Claude Sonnet 4.5 for Long-Horizon Agents
Faster prompt-only models excel in simple queries. They falter in multi-hour, tool-heavy workflows that require sustained focus. Claude Sonnet 4.5 addresses this gap with proven endurance.
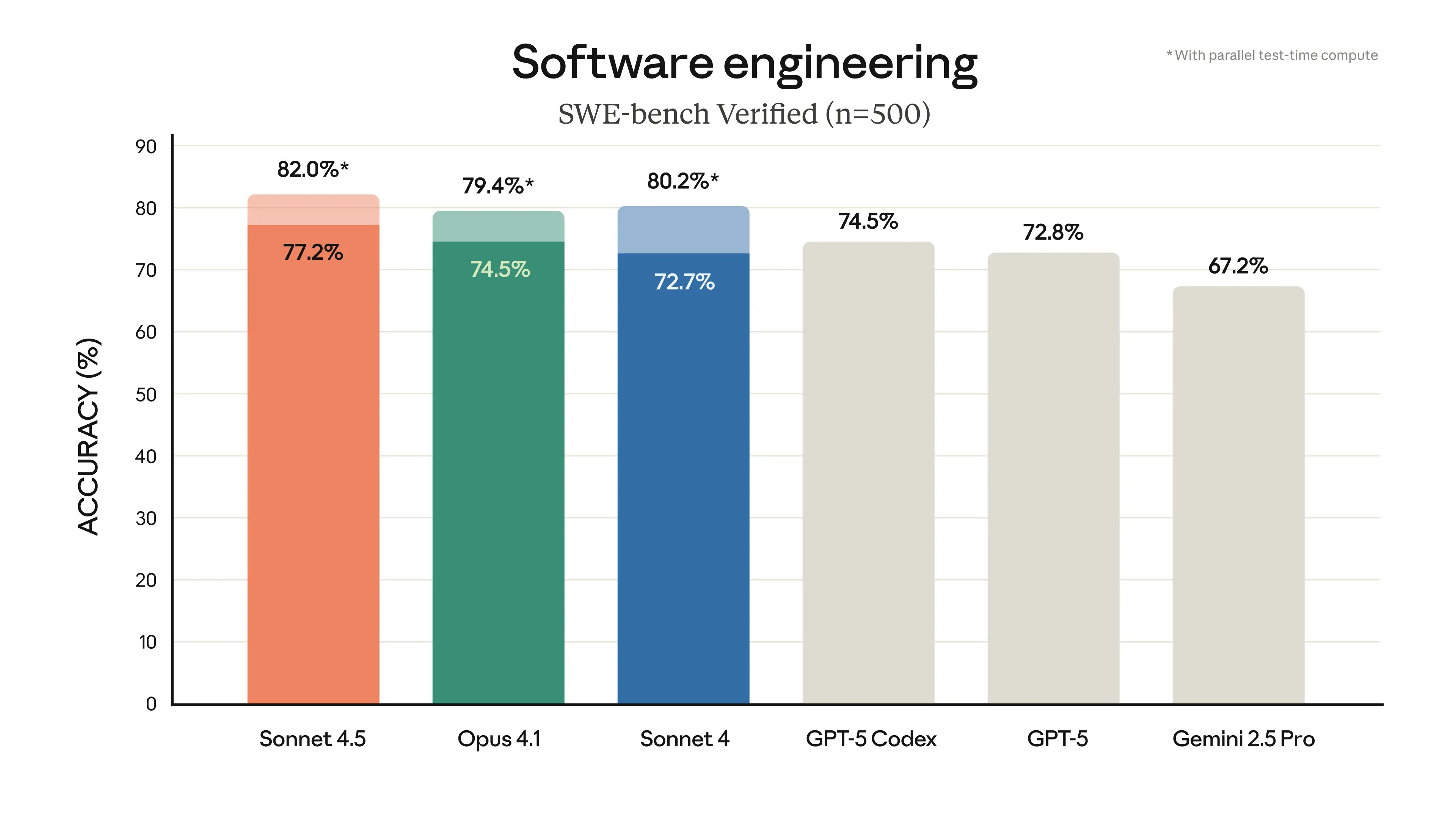
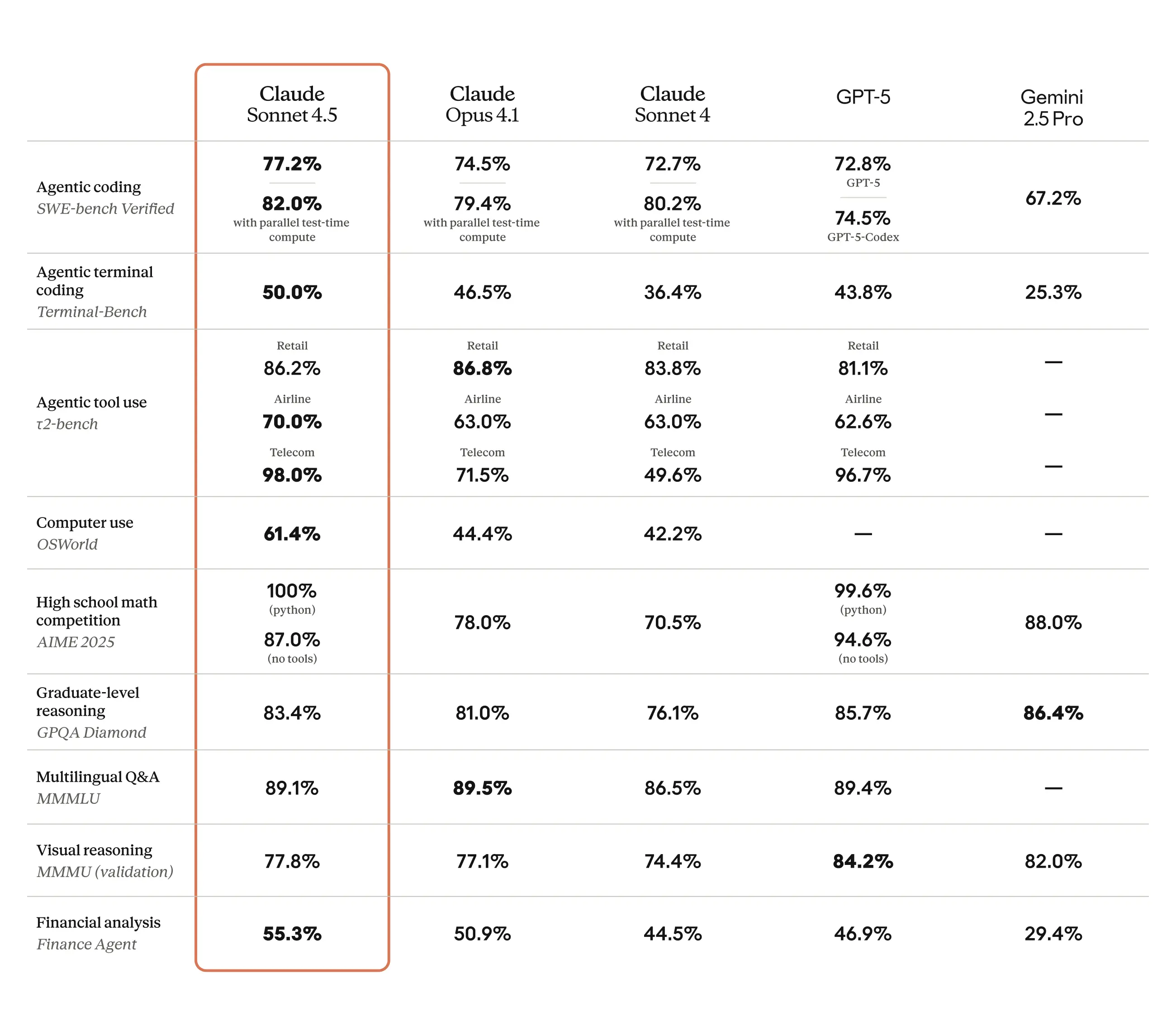
Anthropic claims that it maintains autonomy for over 30 hours in complex tasks. It leads the SWE-bench Verified leaderboard at 77.2 percent and 82 percent with parallel test-time compute.
Source: Anthropic | Introducing Claude Sonnet 4.5
OSWorld results hit 61.4 percent, highlighting superior computer control. Claude Sonnet 4.5 optimizes for agent reliability, not just raw IQ.
Source: Anthropic | Introducing Claude Sonnet 4.5
Impact on Engineering Teams
Agents often fail in recovery from errors. Claude Sonnet 4.5 changes that for teams shipping features. It handles bad tool calls with checkpoints and rollbacks, ensuring smooth progress.
Also, interruptions no longer derail workflows. The model resumes context seamlessly, drawing on memory tools for continuity. Grounding stays strong across long tasks, reducing hallucinations in extended sessions.
Pricing parity at $3 per million input tokens and $15 per million output tokens supports cost-effective pilots. This is similar to Sonnet 4, which is good. Builders benefit from high-level capabilities, such as context editing, as detailed in the launch announcement. Early adopters report tangible gains in productivity.
Claude Sonnet 4.5 is excellent at software development tasks, learning our codebase patterns to deliver precise implementations. It handles everything from debugging to architecture with deep contextual understanding, transforming our development velocity.
Key Performance Highlights
- Long-horizon autonomy claims reach over 30 hours for complex, multi-step tasks like autonomous coding.
- SWE-bench Verified scores around 77.2 percent and 82.0 percent on the official board serve as a proxy for repo-grounded edits in real GitHub scenarios.
- OSWorld computer-use score near 61.4 percent suggests stronger desktop and browser control compared to prior models.
- Early integrator results from Devin show 2× faster performance and +12 percent on internal dev evaluations after adopting Sonnet 4.5.
Validate OSWorld and SWE-Bench on Your Stack
Public benchmarks promise impressive AI performance. Yet, they often fall short when applied to unique company repos and complex infrastructure. Consider how SWE-bench Verified and OSWorld act as reliable proxies for coding fixes and computer tasks.
These tools simulate real-world challenges with constraints such as tool limits and test executions. Still, custom elements like proprietary tests, API secrets, and unreliable services demand internal validation. Teams achieve this by replicating scores through hidden flags, golden datasets, and secure sandboxes.
Crafting a Solid Validation Plan
Start validation with focused, impactful tasks such as triaging flaky tests. Define success through precise criteria that measure real gains. Capture details on tool invocations, total runtime, and retry counts to benchmark efficiency.
Stack these against existing workflows to spot improvements in pull request speed. Monitor success rates for tools and how often rollbacks occur to expose weaknesses. Experts in forums like LessWrong stress vigilance on situational awareness, noting that benchmarks may not fully transfer to production environments.
This approach uncovers hidden issues early. It turns abstract scores into actionable insights for your stack.
Setting Up Your Eval Harness
- Datasets: Pull from key repositories and add concealed canary issues to thoroughly test edge cases.
- Metrics: Focus on golden test pass rates, time spent reviewing pull requests, and overall revert frequencies for clear outcomes.
- Constraints: Limit actions to branch writes, apply credential rate limits, and use temporary sandboxes for security.
- Documentation: Include detailed logs with every pull request to simplify reviews in daily meetings.
Use the Agent SDK to Compose Subagents
Teams struggle with agents that spread errors widely and slow down workflows. To address this, structure them as Planner to Executor subagents to Verifier for better control. By doing this, you allow each component to get scoped permissions, dedicated memory, and optional model choices.
Parallel tool execution accelerates workflows, while isolation enhances safety. The Claude Agent SDK enables this setup for reliable, long-horizon agents. Explore the guide for implementation details.
The pattern draws on established architectures, such as those in recent safety research. Planners decompose tasks and gather context through searches. Executors handle actions with tools, often in parallel for speed.
Verifiers assess outputs using rules, LLM judgments, and feedback loops. This modular design prevents cascading failures in multi-step jobs. Recent benchmarks show gains in autonomy and reliability.
Practical Architecture for Repo Operations
Complex repo tasks overwhelm single agents without decomposition. A planner breaks down issues into steps like code edits and testing. Executor subagents handle specifics, such as writing files or running builds.
A verifier enforces golden tests and policy checks before merges. Cognition redesigned Devin around Sonnet 4.5, shifting agent assumptions for 2× speed and +12 percent end-to-end quality. This setup supports multi-hour jobs with proactive verification.

Engineering Hooks
- 1
Scoped tools
Assign per-subagent shells, editors, and API keys to minimize overreach risks. - 2
State management
Use minimal shared memory with explicit context edits and compaction for long tasks. - 3
Parallelization
Run independent subagents for search, build, and test to reduce overall time. - 4
Verification
Implement policy gates, test checks, and LLM judges before deployment actions.
Ship Safely with Checkpoints, Memory, and Guardrails
So, what stops long-running agents from veering off course or causing real trouble?
Checkpoints.
Checkpoints let teams roll back after messy tool calls, keeping errors in check. Memory and context editing hold the plan steady over time. Guardrails lock actions to safe zones.
Minimal Policy for Week-One Pilots
Starting pilots without solid rules invites headaches right away. Stick to branch-only writes so changes stay tested and contained. Roll with ephemeral sandboxes for clean runs, plus clear approvals before pushing anything live. Throw in network allowlists and prompt-injection checks, especially for browsing or desktop tasks.
Implementation Steps
- Checkpoint cadence: Make saves after major edits, pre-tests, and before deployments to make fixes a breeze.
- Memory discipline: Jot down goals, limits, and fresh choices clearly to keep agents on track.
- Approval gates: Loop in humans before merges or infra tweaks to spot issues early.
- Safety posture: Sync with ASL-3 checks and have quick overrides ready for jammed runs.
Claude Sonnet 4.5 Safety Versus GPT-5
Agentic workflows demand robust safety to prevent drifts or harms over long sessions. Claude Sonnet 4.5 and GPT-5 both advance safeguards, yet differ in frameworks and focus.
Claude emphasizes structured levels, such as ASL-3, while GPT-5 prioritizes safe completions that preceded refusal-based training.
Claude Sonnet 4.5 operates under ASL-3, with classifiers for CBRN risks and reduced false positives by tenfold since the initial models. GPT-5 uses the Preparedness Framework, classifying high in biological risks after 5,000 hours of red-teaming. Both provide system cards detailing misaligned behaviors.
Key Safety Comparisons
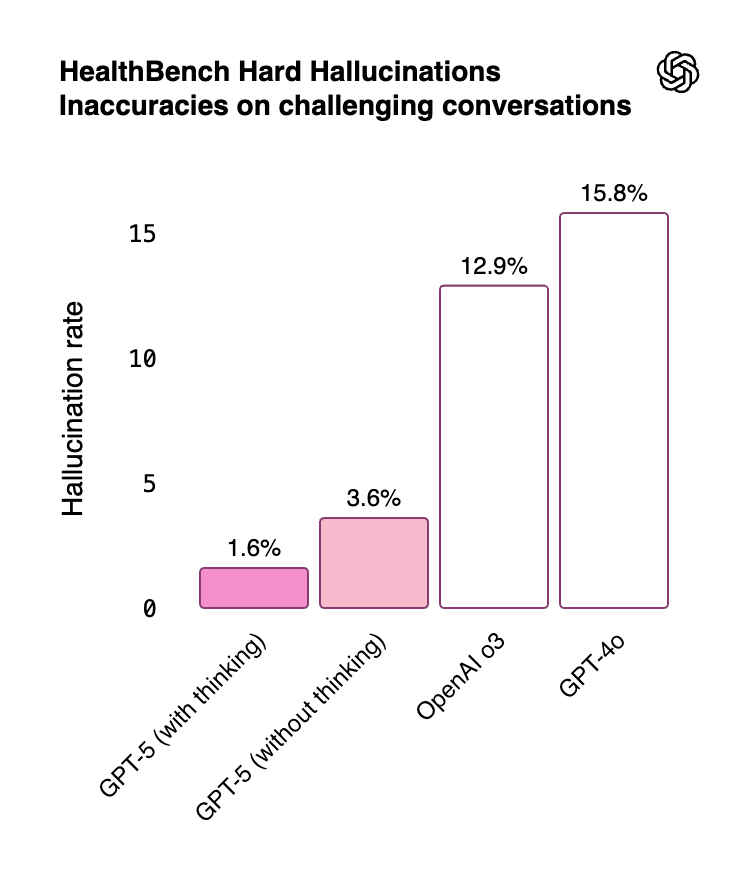
Hallucinations plague extended tasks in agents. Claude Sonnet 4.5 demonstrates strong grounding in benchmarks such as SWE-bench. GPT-5 reduces hallucinations by 45 percent over GPT-4o and 80 percent over o3 models.
Source: Introducing GPT-5
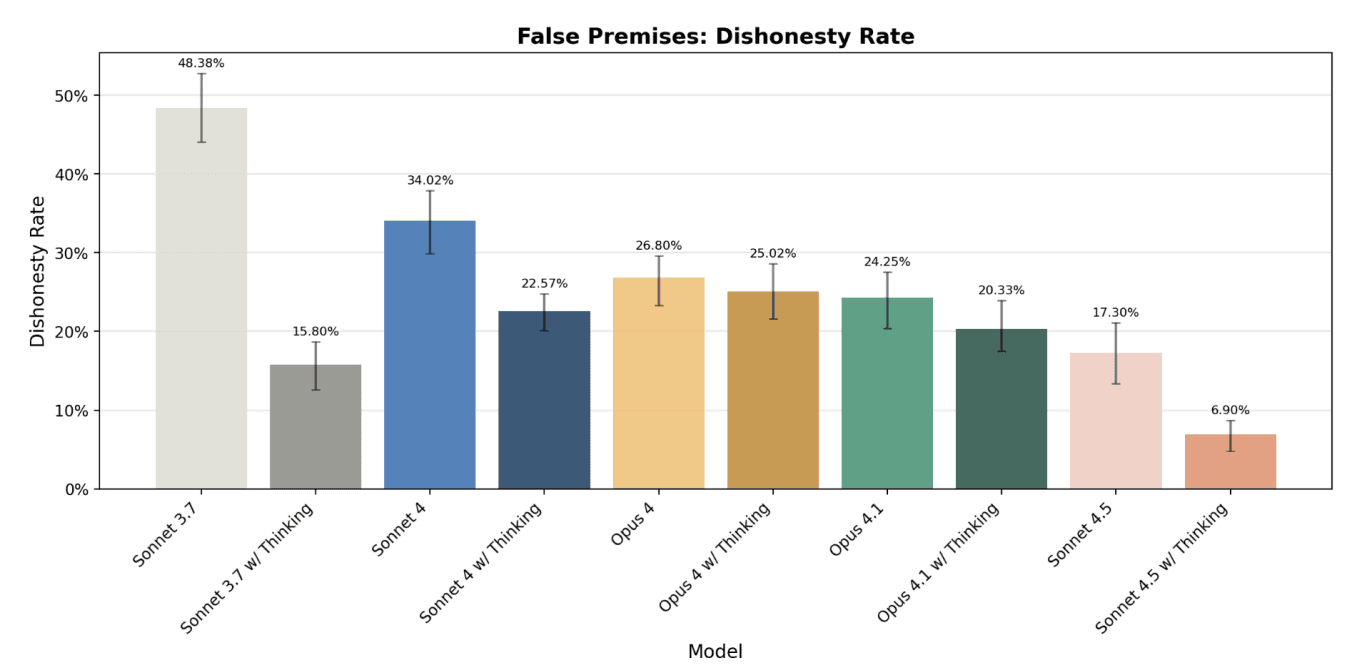
Sycophancy risks biased outputs in team settings. Claude improves compliance metrics in its audit. GPT-5 cuts sycophantic replies from 14.5 percent to under 6 percent.
Source: Claude Sonnet 4.5 System Card
Deception can undermine trust in autonomy. Claude’s system card tracks low deception scores. GPT-5 lowers deception rates to 2.1 percent in production traffic.
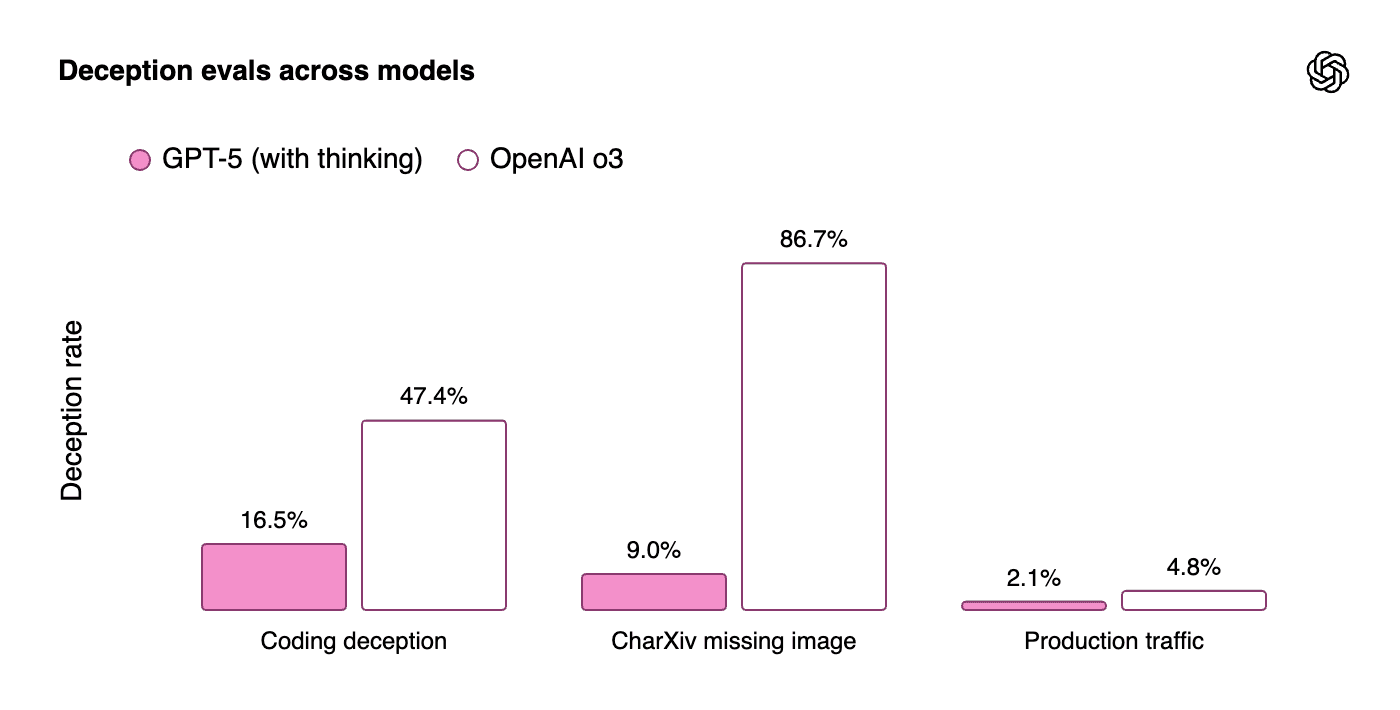
Source: Introducing GPT-5
Industry views favor Claude for safety-sensitive coding, citing stricter specs adherence. GPT-5 excels in nuanced responses via safe completions, reducing overrefusals.
Impact on Engineering Teams
Teams face risks in tool-heavy pilots without tailored guards. Claude's ASL-3 enables bounded operations with checkpoints. GPT-5's safe completions support helpfulness in dual-use areas like virology.
Both models log incidents for audits. Claude reduces CBRN false positives twofold since Opus 4. GPT-5 adds preset personalities to curb sycophancy further.
Compare Sonnet 4.5 with GPT-5 and Gemini 2.5
Claude Sonnet 4.5 excels in long-horizon tasks with 30-hour autonomy. It leads SWE-bench at 77.2 percent for repo edits and OSWorld at 61.4 percent for desktop control. Pricing holds steady at $3 per million input tokens and $15 per million output tokens, accessible via web, mobile, Bedrock, and Vertex.
Quick Decision Tree
Assess workflows before committing to a model. Run small pilots measuring agent-hours saved and time to safe pull requests. Compare end-to-end costs against baselines.
- Pick Sonnet 4.5 for long-horizon repo operations needing sustained autonomy and error recovery.
- Choose it for desktop or browser automation, where OSWorld scores predict reliability.
- Opt for GPT-5 in specialized retrieval stacks, featuring its $1.25 input pricing and strong performance on multimodal tasks.
- Favor Gemini 2.5 Pro for niche multimodal if pipelines standardize on Google tools, at $1.25 input costs.
- Use alternatives when existing infra favors OpenAI or Google for seamless integration.
Closing
Large language models are stepping from prompt helpers to dependable agent systems that plan, act, and recover.
Claude Sonnet 4.5 marks a practical leap:
- 1longer autonomy
- 2better desktop and browser control,
- 3a production-oriented SDK with checkpoints and scoped tools.
That combination reduces brittle failures in coding workflows and shortens the time to a safe pull request. However, adoption should start with small pilots, golden tests, and branch-only writes, then scale by measuring agent-hours avoided and rollback rates.
Used in this way, Sonnet 4.5 helps teams build and operate real coding agents rather than demos, while keeping costs and risks under control.
Glossary
Long-Horizon Agent
Long-horizon agents execute sequences of steps over hours or days while integrating tools. Their reliability hinges on memory retention, error recovery, and built-in guardrails beyond basic reasoning.
Claude Sonnet 4.5 enhances this through checkpoints, context edits, and safer tool interactions. Benchmarks like SWE-bench and OSWorld simulate these demanding workloads effectively.
Computer Use
Computer use enables models to control desktops or browsers for end-to-end task completion.
OSWorld assesses this with realistic scenarios and strict success criteria. High scores reflect better sequencing of tools, sustained focus, and robust recovery mechanisms. Claude Sonnet 4.5 advances in this area over earlier versions, boosting agent performance in practical settings.
SWE-bench Verified
SWE-bench Verified uses a curated set of GitHub issues to gauge model effectiveness in fixing code under strict tool rules. It prioritizes understanding repo structures, compiling changes, and running tests accurately. Claude Sonnet 4.5 leads the leaderboard with approximately 77.2 percent, although setups influence the exact figures.
Results provide guidance but require adaptation for specific environments.
OSWorld
OSWorld evaluates AI in handling genuine desktop and browser automation across varied scenarios. It tests skills in planning actions, maintaining attention, and managing tools safely. Claude Sonnet 4.5 scores around 61.4 percent, marking progress in autonomous computer interactions. Companies benefit from custom runs to verify alignment with their workflows.
Agent SDK
Agent SDK provides a toolkit for composing agents and subagents atop Claude models. It standardizes tool use, memory handling, and permission patterns, helping teams skip custom code. The SDK promotes safer orchestration for extended tasks through documentation on initialization and best practices.
Access the overview at https://docs.claude.com/en/api/agent-sdk/overview for production setups.
Subagent
Subagents specialize in narrow roles within broader workflows to enhance focus. They isolate context and credentials, curbing failures from spreading across systems. This design fosters parallelism and eases debugging in complex operations. Subagents improve throughput and safety for jobs spanning hours or more.
Checkpoint
Think of checkpoints as snapshots grabbing files, choices, and plans at key spots. When things go wrong, agents rewind instead of piling on mistakes. This slashes time lost and eases reviews for busy teams.
Sonnet 4.5 weaves these into Claude Code for easy bounce-back.
ASL-3
ASL-3 outlines Anthropic’s rules for powerful yet controlled systems. Built-in classifiers watch chats to nix dangers like risky moves or sneaky injections. Sonnet 4.5 sits comfy under ASL-4 limits, capping wild autonomy. Still, add your own audits and controls, as urged in the 2025 system card.