
Helicone and Adaline both help teams ship LLM features with fewer surprises in production. They overlap on observability and cost visibility, but they take different routes to reliability.
Helicone is an open-source-first observability layer and AI Gateway. It captures requests, costs, and latency, then adds tools like caching, rate limits, prompt management, and evaluation scores.
Adaline is a prompt-to-production operating system. It treats prompts like deployable assets: iterate with datasets, evaluate at scale, deploy through environments, and monitor live behavior with continuous evaluations that surface regressions early.
The core difference is that Helicone helps you observe and optimize LLM calls. Adaline connects observability to controlled releases and repeatable improvement across the full prompt lifecycle.
Helicone
Helicone is an open-source LLM observability platform and AI Gateway designed to instrument LLM traffic with minimal integration work. It logs requests and responses, tracks spend and latency, adds caching and rate limiting, and supports prompt templates and scoring.
Helicone Features
- Observability and tracing: Debug LLM behavior with detailed request logs.
- Cost tracking: Monitor spend across providers, models, and users.
- Gateway controls: Caching, retries, and custom rate limits.
- Prompt management: Store templates with variables and deploy via the gateway.
- Evaluation signals: Attach scores and feedback to requests and analyze trends.
- Best for: Teams that want a flexible gateway plus observability, with self-hosting as an option.
Things to Consider
Helicone provides strong visibility and practical cost controls. However, teams still define the broader “prompt ops” loop themselves: how prompt changes are promoted, which evaluation suites gate releases, and how production signals feed back into iteration.
Helicone also shines when you need gateway primitives close to traffic. Caching can eliminate repeated calls during debugging. Custom rate limits can cap spend by request count or cost. Prompt caching can reduce provider token charges for repeated context. If you already run prompt changes through code review, Helicone can become the observability and control plane you standardize across services.
Adaline
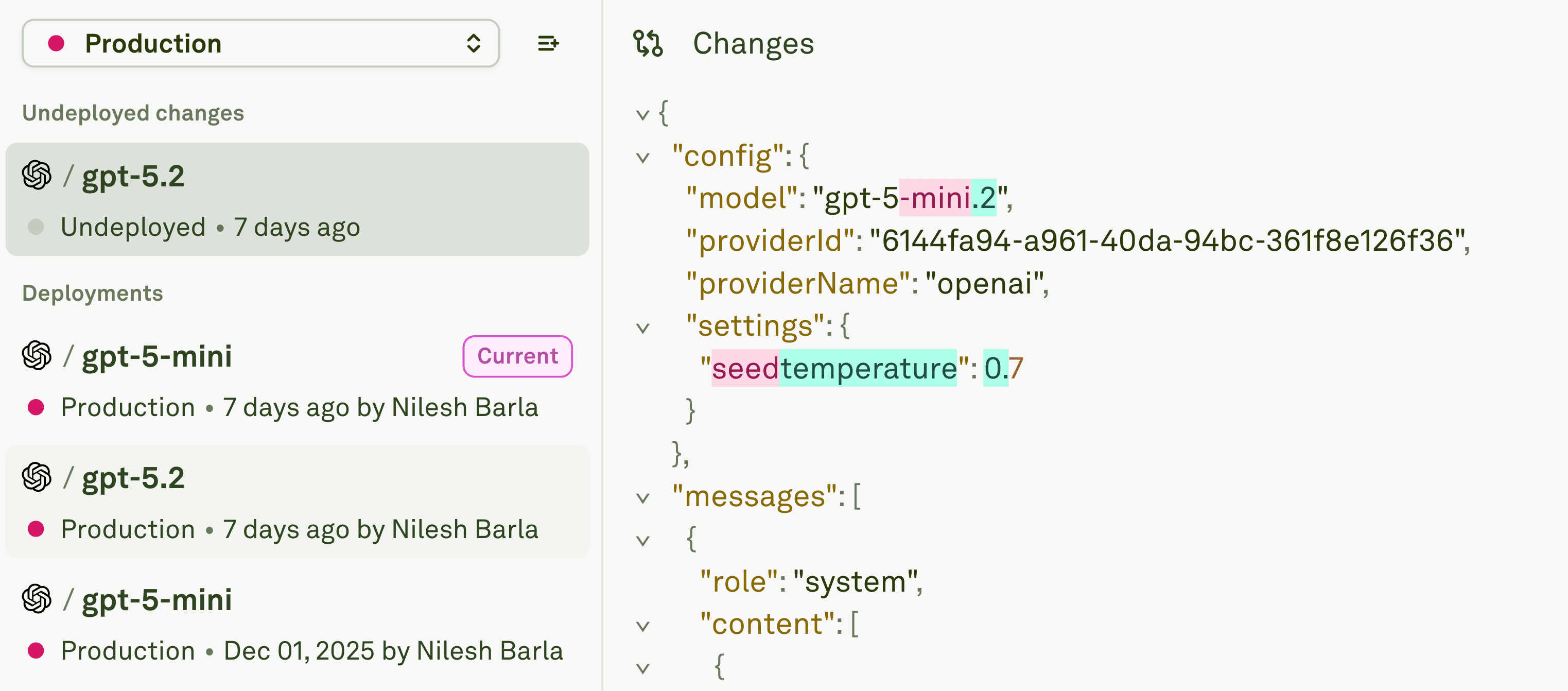
Adaline provides version control to their users.
Adaline is a single collaborative platform where product and engineering teams iterate, evaluate, deploy, and monitor prompts for LLM applications and agents. It is built to turn prompt work into an engineering workflow with version history, environments, and measurable quality signals.
Adaline Features

Adaline Editor and Playground that allows users to design and test prompts with different LLMs. Users can test their prompts using tool calls and MCP as well.
- Collaborative iteration: Build prompts with variables, run them across models, and test on real datasets.
- Automated evaluation: LLM-as-a-judge, text matchers, custom JavaScript logic, plus cost, latency, and token measurements.
- Deployment discipline: Promote prompts across Dev, Staging, and Production with tracked history and instant rollback.
- Production monitoring: Inspect traces and spans, search by prompt or error, and watch time-series charts for latency, cost, token usage, and evaluation scores.
- Continuous evaluations: Re-run evals on live traffic samples to detect regressions early.
- Cross-functional workflow: One system of record for PMs and engineers, reducing handoffs and rework.
Adaline’s monitoring is designed to answer the question: “Did this prompt change move the needle?” Time-series charts make token spikes and latency regressions obvious. Because evaluation scores are tracked alongside cost and errors, teams can decide whether a cheaper model is actually acceptable. This tight loop is why Adaline works well for cross-functional teams.
Things to Consider
Teams shipping customer-facing AI where prompt changes must be safe, auditable, and measurable. If you want to treat prompts like code releases and make evaluations a default gate, Adaline is the more complete operating model.
Comparison Table
Workflow Comparison
Helicone workflow for a production quality issue:
- Find the failure in traces and inspect the request.
- Attach scores or feedback so the issue is trackable.
- Curate a repeatable test set from real examples.
- Validate a revised prompt with experiments or evals.
- Promote the change using your own release process.
Adaline workflow for a production quality issue:

Screenshot of observability results in the Adaline dashboard.
- Find the failure in traces and inspect the prompt version.
- Add failing cases to a dataset and define an evaluator.
- Run an evaluation to compare prompt versions.
- Promote the winner from Staging to Production with a tracked release.
- Keep continuous evaluations running to catch the next regression early.
The practical difference: Adaline ships the lifecycle as a coherent loop. Helicone gives you visibility and levers, but you assemble the release discipline around it.
Conclusion
Choose Adaline when:
- You need a system of record for prompts, versions, environments, and releases.
- You want evaluation at scale before shipping and continuously after.
- You need Dev/Staging/Prod promotion and rollback as a first-class workflow.
- PMs and engineers must collaborate in one workspace with shared artifacts and results.
- You want production traces to feed directly into datasets and evaluation suites.
Choose Helicone when:
- You primarily want an open-source observability gateway with strong cost analytics.
- You want caching, rate limiting, and routing in the instrumentation layer.
- Self-hosting and infrastructure control are hard requirements.
- You already have a mature release process and need better visibility.
For production AI, the question is not only what happened. It is whether you can improve it safely, repeatedly, and with confidence. That is where Adaline’s full lifecycle workflow is the differentiator.
Frequently Asked Questions (FAQs)
Which tool is better for controlling LLM spend?
Both help, but differently. Helicone excels at gateway-level controls, such as caching and rate limits. Adaline prevents waste through evaluation and controlled rollout, so you do not ship a prompt change that quietly doubles token usage.
Which tool is better for prompt versioning and rollback?
Both support prompt history and rollback, but Adaline pairs versioning with environments and promotion workflows. That matters when you need a clear answer to what is live in Production and a safe path from Staging to users.
Can I run evaluations and track quality over time?
Yes, in both, but the workflow differs. Helicone supports request-level scoring. Adaline is centered on evaluations: datasets, evaluators, reports, and continuous re-runs on live traffic samples.
What should I choose if I need one platform for promptOps?
Adaline. If your goal is prompt ops as a discipline, you need iteration, evaluation, deployment, and monitoring in one loop. Helicone is excellent as an observability gateway, but Adaline is designed as the operating system for the full prompt lifecycle.