
Benchmark Saturation & the Need for a “Last Exam”
TL;DR: Humanity's Last Exam addresses benchmark saturation where top AI models score >90% on traditional tests, making progress measurement impossible. Created by experts across 100+ domains, HLE questions stump even the best models (scoring <30%), revealing true AI limitations. Its innovative design includes anti-gaming features, multi-modal testing, and calibration measurement, providing a more realistic assessment of AI capabilities for product teams and policymakers.
The Current AI Evaluation Crisis
The AI community faces a serious problem. Our best tools for measuring language model capabilities have reached their limits. Leading benchmark saturation occurs when top models consistently score above 90% on standardized tests.
This saturation creates a false ceiling that masks actual progress. When GPT-4 scored over 90% on MMLU (Massive Multitask Language Understanding), the benchmark effectively lost its ability to distinguish meaningful improvements in newer models.
Source: GPT-4
The pattern repeats across multiple evaluation standards:
- MMLU exceeded 90% accuracy with the latest models
- MATH dataset quickly progressed from <10% to >90% in just three years
- GSM8K showing similar saturation patterns
This rapid saturation limits our understanding of AI capabilities at the development frontier.
Why Traditional Benchmarks Fall Short
Traditional benchmarks fail to reveal crucial differences between top-performing models. This leads to three significant problems:
- 1
Measurement limitations
When models max out scores, we cannot accurately measure improvement - 2
False confidence
Teams develop unrealistic expectations about model capabilities - 3
Hidden weaknesses
Critical gaps in knowledge remain undetected despite high scores
The post-MMLU era demands new evaluation approaches. Research teams at Scale AI and the Center for AI Safety recognized this evaluation crisis when developing Humanity’s Last Exam.
The Need for a Final Academic Benchmark
Product teams face significant risks when relying on saturated benchmarks. High scores on existing tests create a misleading impression of model capabilities and reliability. These scores rarely translate to real-world performance.
When I released the MATH benchmark in 2021, the best model scored less than 10%; few predicted that scores higher than 90% would be achieved just three years later.
This rapid progression underscores why we need increasingly complex standards. Humanity’s Last Exam represents an attempt to create the final closed-ended academic benchmark with sufficient headroom to measure progress for years to come accurately.
The exam focuses on questions that specifically test the limits of AI knowledge at the frontiers of human expertise. We can truly understand their capabilities and limitations only by pushing models to their breaking points.
Origins of Humanity’s Last Exam (HLE)

A sample of HLE dataset | Source: Humanity’s Last Exam
HLE emerged as a joint initiative between Scale AI and the Center for AI Safety (CAIS). The project represents an ambitious effort to create what its founders call the "final closed-ended academic benchmark with broad subject coverage."
The benchmark was developed under the leadership of Dan Hendrycks, CAIS co-founder and executive director, and Alexandr Wang from Scale AI. Their vision was to create an evaluation that would remain challenging even as AI systems continue to advance rapidly.
Creating the Ultimate Challenge
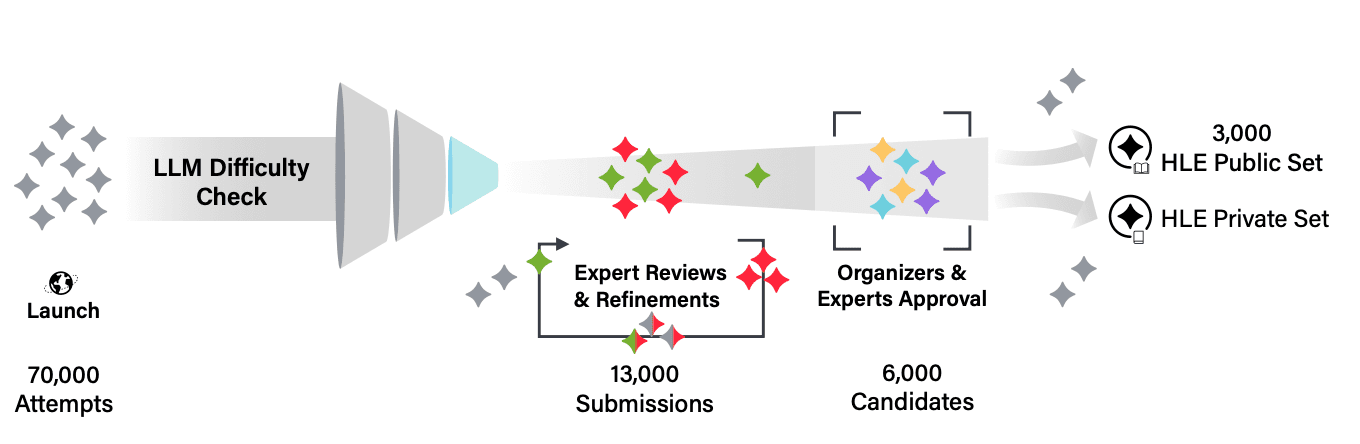
The development workflow diagram of HLE | Source: Humanity’s Last Exam
The development process for this crowdsourced AI benchmark followed a rigorous path:
- 1Global expert recruitment (nearly 1,000 contributors)
- 2Collection of 70,000+ initial question submissions
- 3Selection of 13,000 questions for human expert review
- 4Final curation to 3,000 questions for public release
What might be the ultimate test, meticulously distilled and designed to challenge the world's most advanced models at the frontiers of intelligence.
The Expert Network Behind HLE
The benchmark draws its strength from its diverse contributor base:
To incentivize high-quality submissions, the project established a $500,000 prize pool. This included:
- $5,000 USD for each of the top 50 questions
- $500 USD for each of the next 500 best submissions
The substantial prizes attracted world-class expertise across domains. Contributors also received co-authorship opportunities on the final research paper.
A Frontier Knowledge Test
What sets HLE apart is its focus on questions at the absolute edge of human knowledge. The questions intentionally push beyond standard academic tests into territory where even specialized experts might struggle.
The exam covers multiple formats, including text-only and multi-modal challenges with images and diagrams. Each question underwent testing against frontier AI models to ensure it truly represents a challenging evaluation standard.
By bringing together elite global expertise, HLE aims to measure how close AI systems are to matching specialist human knowledge across diverse academic fields.
Inside the HLE Blueprint: Multi-Modal, Expert-Level, Closed-Ended
Anatomy of an Ultimate Challenge
Humanity’s Last Exam contains approximately 3000 questions spanning over 100 subject areas. The benchmark’s architecture follows a carefully designed blueprint to ensure maximum effectiveness as a multi-modal benchmark.
The question formats include:
- 76% short-answer (exact-match) questions
- 24% multiple-choice questions
- 10-14% vision-based tasks requiring image analysis
This diversity ensures the benchmark tests both reasoning capabilities and visual understanding across academic domains.
Question Distribution by Field

Question distribution of HLE | Source: Humanity’s Last Exam
The exam covers an extensive range of academic disciplines:
Each subject features questions at a graduate or expert level, requiring deep domain knowledge to solve.
Preventing Memorization with Private Test Sets
A key innovation in HLE's design is its two-part structure:
- Public development set for research and model improvement
- Private held-out evaluation set to prevent gaming
The private test subset allows ongoing assessment of model overfitting. When models perform significantly better on public questions than on similar private ones, it reveals potential memorization rather than true understanding.
Each question in the final dataset underwent confirmation as:
- Precise and unambiguous
- Solvable with domain knowledge
- Non-searchable via simple internet queries
- Original or representing non-trivial synthesis of published information
This meticulous attention to quality makes HLE uniquely positioned to serve as a durable benchmark for the most advanced AI systems, potentially for years to come, despite rapid model improvements.
Leaderboard Deep-Dive: GPT-4o, Gemini 2.5, o3 vs Humans
Early Results Show Significant AI Knowledge Gaps
The initial SEAL leaderboard results for Humanity's Last Exam reveal striking limitations in current AI systems. Even the most advanced models struggle with expert-level questions, achieving surprisingly low scores:
These single-digit scores contrast sharply with the >90% accuracy these same models achieve on other benchmarks like MMLU. This confirms HLE's effectiveness at testing the frontiers of AI capabilities.
Rapid Progress Through Specialized Techniques
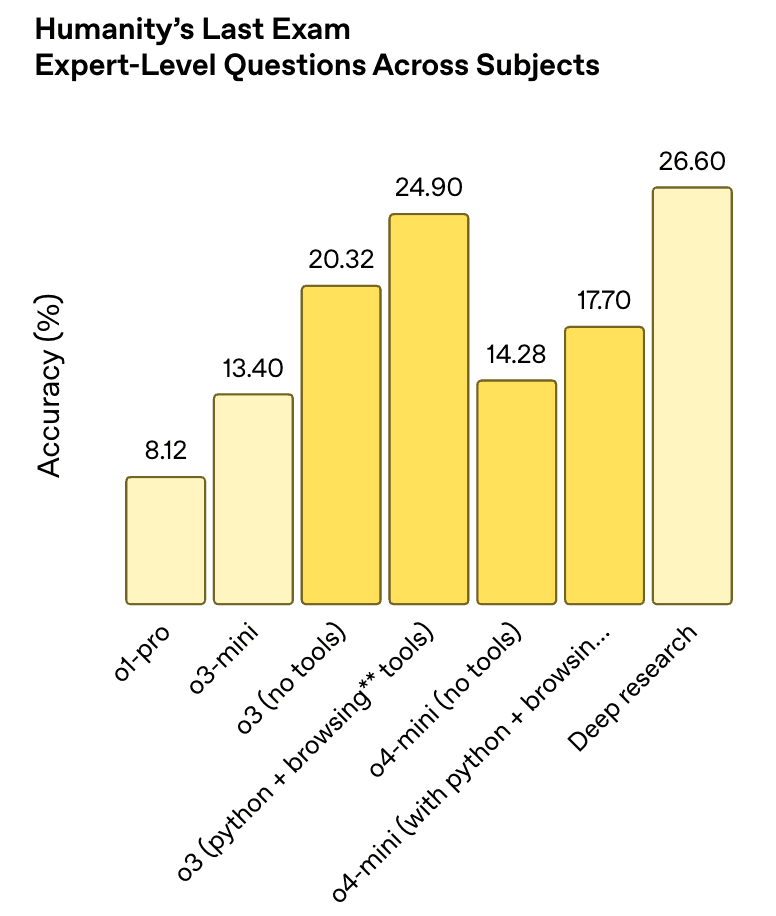
Performance graph of OpenAI models on HLE | Source: Introducing OpenAI o3 and o4-mini
Despite initial low scores, improvement has happened quickly. By April 2025, newer models showed notable progress:
- 1o3-high: 20.3% accuracy
- 2OpenAI "Deep Research": 26.6% accuracy
This rapid climb suggests two important insights:
- Specialized research techniques can overcome initial limitations
- The ceiling for improvement remains far from human expert performance
The Calibration Problem
Beyond raw accuracy, AI calibration error presents a serious concern. The RMS calibration error measures how well models assess their own confidence. Perfect calibration means a model claiming 70% confidence should be correct 70% of the time.
Current models show poor calibration on HLE:
- RMS errors between 70-90% across all tested systems
- Models frequently express high confidence in incorrect answers
- This pattern reveals a fundamental reliability problem
This unreliable self-assessment creates serious trust issues. When models confidently provide incorrect answers (hallucinate), users face greater risks than when models acknowledge uncertainty.
The Reasoning Token Cost
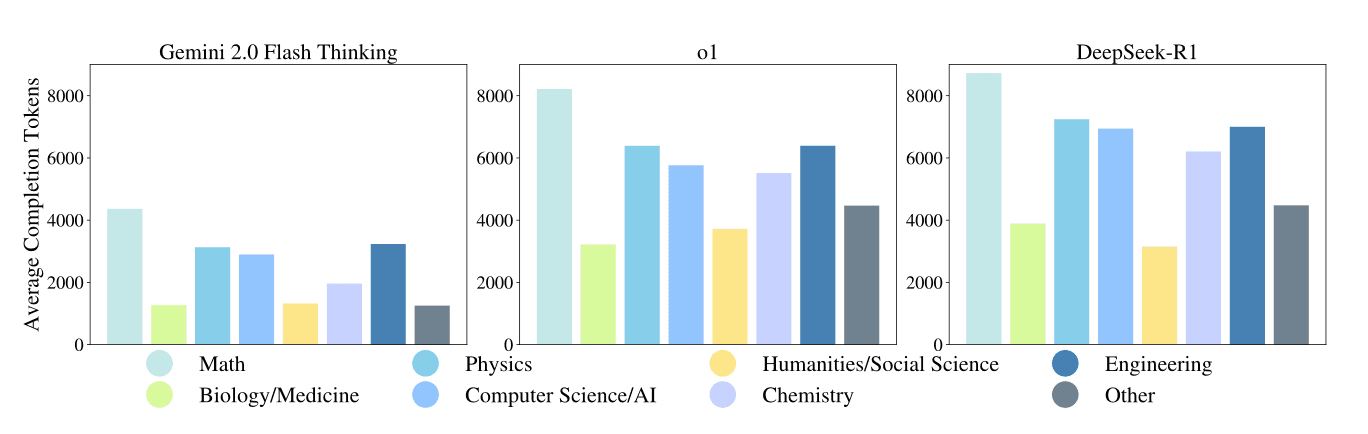
Plot showing average completion tokens of reasoning models | Source: Humanity’s Last Exam
Models with "reasoning" capabilities use significantly more computation. The token count comparison reveals this trade-off:
- Standard models: 200-800 tokens per response
- Reasoning models: 2,000-8,000 tokens per response
This 10x increase in computational resources yields only 2-3x improvement in GPT-4 HLE score. This efficiency gap highlights the immense computational costs of approaching human-level expertise.
While progress continues, the benchmark confirms that a substantial gap remains between even the most advanced AI systems and human expert knowledge across academic domains.
Why HLE Matters for AI Safety & Policy
Revealing True AI Limitations
Humanity's Last Exam serves a crucial function beyond standard benchmarking. It exposes fundamental gaps in frontier AI systems that might otherwise remain hidden. These revelations have direct implications for AI safety metrics and governance approaches.
The benchmark's results highlight two critical safety concerns:
- 1
Reasoning limitations
Even top models achieve <30% accuracy on expert questions - 2
Overconfidence problem
Models express high confidence in wrong answers
This combination of poor performance and poor calibration creates significant risk. AI systems deployed in critical domains may make mistakes without appropriate caution signals to users.
Informing Research Priorities
HLE's detailed breakdowns guide alignment researchers toward specific improvement areas:
By targeting these weaknesses, researchers can develop more reliable AI systems that acknowledge their limitations appropriately.
Implications for AI Governance
Policymakers must consider HLE results when developing AGI policy benchmarks. The exam offers a dual narrative with significant policy implications:
Progress Signal
The rapid improvement from initial scores (3-5%) to more recent results (20-26%) demonstrates:
- Frontier models advance quickly
- Research tactics can overcome initial limitations
- The ceiling for performance remains undefined
Warning Signal
Despite progress, critical gaps remain:
- Expert-level knowledge still exceeds current AI capabilities
- Self-assessment abilities lag behind raw performance
- Computational costs for improvements grow exponentially
This nuanced picture helps regulators balance innovation with caution. HLE provides concrete evidence that advanced systems still have significant limitations, especially in specialized knowledge domains.
For safety researchers, the benchmark offers a standardized way to measure both progress and remaining challenges. This shared reference point enables more productive discussions about risk assessment and appropriate guardrails for increasingly capable systems.
As models continue improving on HLE, the benchmark will help track the narrowing gap between AI capabilities and human expertise across academic disciplines.
The Benchmark Lifecycle: What Comes After HLE?
Predicting HLE's Useful Lifespan
How long will Humanity's Last Exam remain challenging? The benchmark lifecycle of previous tests suggests caution in making predictions. Dan Hendrycks notes that the MATH benchmark moved from <10% to >90% accuracy in just three years—far faster than experts anticipated.
For HLE, competing predictions exist:
The private held-out test set provides crucial protection against overfitting. This design element may extend HLE's useful life significantly compared to previous benchmarks.
Beyond Traditional Question-Answer Tests
When HLE eventually saturates, what comes next? Several emerging evaluation approaches may take its place:
- 1
AI-generated evaluations
Tests that evolve alongside model capabilities - 2
Interactive assessment
Dynamic evaluations that adapt based on responses - 3
Real-world agent evaluations
Testing AI behavior in simulated environments
Researchers increasingly recognize that benchmarking approaches must evolve alongside AI capabilities. Static benchmarks have inherent limitations regardless of difficulty.
HLE may be the last academic exam we need to give to models, but it is far from the last benchmark for AI.
The future of AI evaluation will likely shift toward human-in-the-loop assessment methods. These approaches combine automated testing with human judgment to create more nuanced and adaptable evaluation standards. This hybrid approach may prove more resistant to saturation than even the most challenging fixed benchmarks.
Conclusion
Humanity's Last Exam (HLE) represents a crucial innovation in AI evaluation. This benchmark contains approximately 3,000 expert-crafted questions across 100+ academic domains, specifically designed to challenge even the most advanced AI systems.
HLE stands apart through several key features:
- Multi-modal testing (text and image-based questions)
- Graduate-level difficulty requiring specialized knowledge
- Public and private evaluation sets to prevent gaming
- Rigorous development by nearly 1,000 global experts
Current leading models achieve only 2-20% accuracy on HLE—a stark contrast to their >90% performance on previous benchmarks. This performance gap reveals important limitations in frontier AI systems.
Why Product Leaders Should Pay Attention
For product leaders working with AI technologies, HLE offers valuable insights:
- 1
Realistic capability assessment
HLE provides an honest picture of what today's most advanced models can and cannot do, helping set appropriate expectations - 2
Risk identification
The poor calibration scores (70-90% error) highlight reliability issues that could affect product trustworthiness - 3
Development roadmap guidance
The benchmark identifies specific areas where improvements would yield the greatest benefits - 4
Safety considerations
HLE helps teams understand where human oversight remains necessary in AI-augmented workflows
As AI capabilities advance, HLE will serve as a consistent reference point for measuring progress. Product teams can use HLE scores to make informed decisions about which technologies to adopt and how to implement them responsibly. By understanding both the rapid improvements and persistent limitations revealed by this benchmark, leaders can build more realistic roadmaps for AI integration in their products.