
As AI models tackle increasingly complex tasks, their ability to allocate compute dynamically during inference is becoming a game-changer. Time to Compute (TTC)—the measure of how much compute a model expends per query—directly influences its reasoning depth, accuracy, and overall intelligence.
Traditionally, AI efficiency was measured by train-time compute, where models consumed vast resources during pretraining but used a fixed, lightweight process at inference. This worked well for simple tasks but limited adaptive problem-solving. Now, leading models like GPT-4-turbo and Grok-3 are flipping the paradigm: rather than treating all queries equally, they allocate more compute to complex prompts while keeping trivial requests efficient.
This shift unlocks major benefits:
- 1
Deeper reasoning and accuracy
Instead of rigid token processing, models can dynamically allocate FLOPs for multi-step logical deductions. - 2
Efficient resource utilization
Not every query needs full model depth—adaptive compute allocation ensures power is used only when necessary. - 3
Breakthroughs in problem-solving
From long-form reasoning to mathematical proofs, TTC optimization allows LLMs to tackle problems previously beyond reach.
In this article, we’ll explore:
- 1How TTC impacts model accuracy and efficiency.
- 2Techniques leading AI labs use to optimize inference compute.
Let’s dive in.
I. Understanding test-time compute
1.1 What is Test-Time Compute?
TTC refers to the computational resources an AI model uses during inference. This phase is when it processes new data to generate outputs. Optimizing TTC is important for enhancing AI systems' efficiency, speed, and scalability, especially as models become more complex.
What makes TTC so important?
Single-Pass Inference vs. Multi-Step Reasoning
System 2 thinking in AI
The concept system 2 thinking aligns with the psychological theory of System 2 thinking, involving slow, deliberate, and analytical thought processes. Implementing System 2 thinking in AI means designing models that allocate extra computational effort during inference for complex reasoning tasks.
Leading models prioritizing TTC
- OpenAI’s o1 Model: Emphasizes multi-step reasoning during inference, effectively handling complex queries.
- xAI's Grok-3 Model: It offers modes like "Think" and "Big Brain," allocating extra computing resources for tasks requiring deeper reasoning, thus improving output quality.
- Enhanced accuracy: Allocating more computing during inference allows for detailed analyses, leading to more accurate predictions.
- Improved reasoning: Multi-step processing enables models to break down complex problems into manageable parts, facilitating better problem-solving strategies.
- Adaptive Computation: Models can adjust their computational effort based on input complexity, optimizing resource use.
- Balancing speed and accuracy: While increased TTC can improve performance on complex tasks, it also demands more computational resources and time. Balancing these factors is essential for deploying efficient and effective AI systems.
1.2 Why test-time compute matters
TTC allows models to engage in deeper reasoning and iterative refinement, leading to more accurate and reliable results.
Some other reasons why TTC matters:
Enhanced model outputs through increased TTC
- Deeper Analysis: Allocating more computational resources during inference allows AI models to perform comprehensive analyses, improving performance.
- Example: OpenAI's o1 model enhances problem-solving by dedicating extra processing time to generate and evaluate multiple solutions, selecting the most effective one.
Iterative refinement and accuracy enhancement
- Self-improvement: TTC enables models to iteratively assess and refine their outputs, similar to human problem-solving.
- Research Findings: Studies show that iterative self-refinement can significantly boost task performance, with outputs preferred by human evaluators and automated metrics over traditional one-step methods.
Adaptability and Generalization
- Dynamic reasoning: Incorporating TTC allows models to adjust their reasoning based on input complexity, enhancing adaptability.
- Versatility: This flexibility is vital for developing general AI systems capable of handling diverse tasks, and improving overall performance.
II. Foundation of scaling laws
2.1 Kaplan scaling saws
In 2020, Jared Kaplan and colleagues introduced empirical scaling laws that describe how neural language model performance improves as key factors are scaled up. These factors include:
- Model Size (N): The number of parameters in the model.
- Dataset Size (D): The amount of training data used.
- Compute (C): The computational resources expended during training.
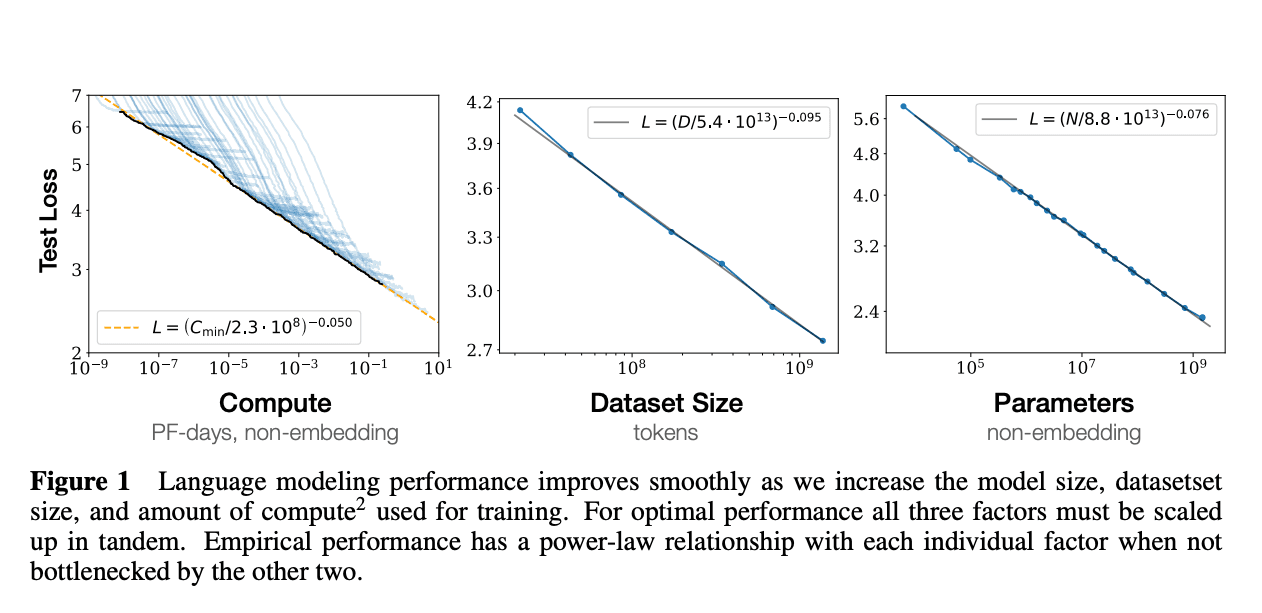
Diagram showing significant improvement in language models as it is scaled up | Source: Scaling laws for neural language models
Their research demonstrated that the cross-entropy loss—a measure of model performance—follows a power-law decline as these factors increase. This relationship is encapsulated in the equation:
Where:
- L: Loss.
- L0: Irreducible loss.
- N0, D0, αX, αD: Empirically derived constants.
This formulation indicates that increasing the model size and training data leads to predictable improvements in performance.
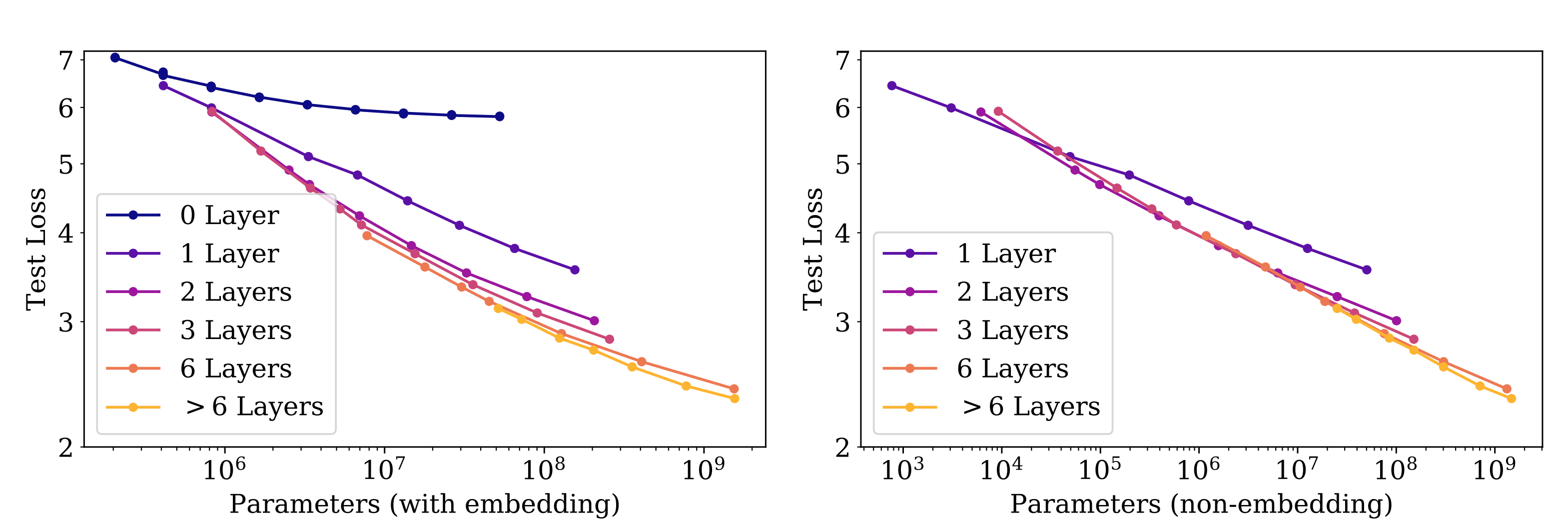
The diagram shows as the size of the model increases in terms of parameters the loss start decreasing. | Source: Scaling laws for neural language models
- Research by Jared Kaplan and colleagues in 2020 revealed that model performance improves predictably as we increase these factors.
- They found that the cross-entropy loss, a measure of model accuracy, decreases following a power-law pattern when scaling up N, D, and C.
Balancing Model Complexity and Efficiency
- While larger models often yield better results, they require more computational power during training and inference.
- Optimizing TTC involves finding a sweet spot between model size and operational efficiency.
- Efficient model architectures can match the performance of larger models but with reduced inference time, making them more practical for real-world applications.
Architectural Choices Impacting TTC
- Decisions about network depth, width, and the use of mechanisms like attention directly influence computational demands during inference.
- Models designed for parallel processing or those utilizing sparse activation can decrease TTC without sacrificing accuracy.
- Thoughtful architectural design is key to achieving efficient and effective AI systems.
Strategic Application of Scaling Laws
- Understanding these scaling laws helps predict how model size and data changes affect performance and resource needs.
- By applying these principles, AI practitioners can design models that use computational resources wisely during inference.
- This approach ensures that performance improvements are achieved without excessive operational costs, leading to AI systems that are both powerful and efficient.
In essence, scaling laws offer a roadmap for enhancing AI model performance. By carefully balancing model complexity with computational efficiency and making informed architectural choices, we can develop AI applications that are both robust and practical.
2.2 Compute-Optimal Scaling
Efficient AI models adjust computing power based on task complexity. This means allocating more resources to challenging tasks and less to simpler ones.

The law states as computing power is directly proportional to performance | Source: Scaling laws for neural language models
Dynamic compute allocation
- Adaptive processing: Models assign computing power according to the difficulty of each task.
- Efficiency: This approach conserves resources without compromising performance.
Pre-Inference complexity estimation
- Assessment: Before processing, the model evaluates the complexity of the input.
- Resource Planning: This evaluation helps in deciding the necessary computing power.
Mathematical framework for compute budget optimization
- Objective: Balance performance with resource use.
- Method: Allocate computing resources to maximize efficiency.
Implications for AI product development
- Cost Management: Efficient resource use reduces operational expenses.
- Scalability: Adaptive models can handle a variety of tasks effectively.
- User Satisfaction: Optimized performance leads to better user experiences.
Incorporating compute-optimal scaling into AI systems ensures they are both powerful and efficient.
III. Advanced test-time compute (TTC) methodologies
In this section, we will discuss the three methodologies used to implement TTC.
3.1 Search Against Verifiers (SAV)
The Search Against Verifiers (SAV) framework enhances AI model outputs by combining solution generation with verification. This approach ensures that only accurate and reliable answers are produced.
Key components:
- Generation: The model creates multiple possible solutions for a given problem.
- Verification: Each solution is checked against specific criteria to confirm its correctness.
- Selection: The best solution, as determined by the verification process, is chosen as the final output.
Implementation techniques
- 1
Best-of-N Sampling
Process: Generate 'N' different responses.
Evaluation: Assess each response using a verifier.
Selection: Choose the response that best meets the criteria. - 2
Beam search
Process: Start with multiple initial solutions.
Evaluation: Iteratively refine each solution, keeping only the top candidates at each step.
Selection: After several iterations, select the most promising solution.
Practical applications
- Text generation: Improves the quality of generated text by selecting the most coherent and relevant responses.
- Code generation: Ensures that produced code snippets are functional and error-free.
- Mathematical problem solving: Verifies the accuracy of solutions to complex math problems.
This pseudocode outlines a basic beam search where:
- sequences holds current solution paths and their scores.model.predict_next generates possible next steps for a given sequence.
- model.evaluate assigns a score to each potential step.
By integrating SAV into AI systems, developers can significantly boost the accuracy and dependability of model outputs, leading to more robust applications.
3.2 Diverse Verifier Tree Search (DVTS)
Diverse Verifier Tree Search (DVTS) enhances AI problem-solving by exploring multiple solution paths simultaneously. This approach increases the chances of finding correct answers, especially for complex tasks.

Various search strategies, including DVTS | Source: Scaling test-time compute
Advantages in solution exploration
- Multiple pathways: DVTS examines various potential solutions simultaneously, reducing the risk of missing the correct answer.
- Enhanced Accuracy: DVTS improves the likelihood of accurate results by evaluating different approaches.
Impact on accuracy across tasks
- Complex problem solving: In areas like advanced mathematics, DVTS has been shown to outperform larger models by thoroughly exploring diverse solution paths.
- General applications: This method enhances performance in tasks where multiple solutions are possible, such as language translation and image captioning.
Practical limitations and ideal use cases
- Computational resources: DVTS requires significant processing power, which may not be feasible for all applications.
- Optimal scenarios: Best suited for tasks where accuracy is critical and justifies the additional computational expense.
Implementation guidelines for AI engineers
- Algorithm election: Incorporate diversity-promoting search algorithms like Diverse Beam Search to generate varied solution paths.
- Verifier integration: Develop robust verification mechanisms to assess and rank the validity of each solution path.Resource management: Balance the search depth with available computational resources to maintain efficiency.
By thoughtfully applying DVTS, AI systems can achieve more reliable and accurate outcomes across a range of complex tasks.
3.3 Majority voting and self-Consistency
Majority voting and self-consistency are techniques that enhance the reliability of AI model outputs by aggregating multiple responses to the same prompt.

Overview of Majority Voting System in LLM | Source: LLM Voting: Human Choices and AI Collective Decision Making
Output aggregation techniques
- Majority voting: The model generates several responses to a prompt; the most frequent answer is selected as the final output.
- Self-consistency: Expands on majority voting by producing diverse reasoning paths for each prompt, and then choosing the most consistent answer among them. This approach improves performance on tasks requiring complex reasoning.
Implementation in TTC frameworks
- Multiple sampling: Generate several outputs for a single prompt using varied reasoning paths.
- Consistency evaluation: Assess the consistency of these outputs and select the most frequent or coherent answer.
Trade-offs between accuracy and computational cost
- Increased accuracy: Aggregating multiple responses can produce more reliable and accurate outputs.
- Higher computational cost: Generating and evaluating multiple responses requires more processing power and time.
Examples of successful implementations
- Mathematical Problem Solving: Self-consistency prompting has improved performance in arithmetic reasoning tasks by evaluating various solution paths.
- Commonsense reasoning: Applying these techniques has improved outcomes in tasks requiring everyday logic and understanding.
By thoughtfully applying majority voting and self-consistency, AI systems can achieve more reliable and accurate results across a range of complex tasks.
Conclusion
Dynamic TTC transforms AI by enabling models to allocate computational resources based on task complexity, enhancing reasoning and efficiency.
Key Learnings
- Adaptive Inference
Allocating more compute to complex tasks improves model accuracy and problem-solving. - Efficient Resource Use
Balancing compute allocation ensures optimal performance without unnecessary resource expenditure.
OpenAI's o1 and xAI's Grok-3 utilize TTC for deeper reasoning during inference. Scaling Insights: Empirical scaling laws guide effective TTC implementation, balancing model size and performance.
Takeaways for AI Engineers
- 1
Implement Adaptive Compute
Design models that adjust computational effort based on input complexity. - 2
Leverage Scaling Laws
Use scaling principles to inform resource allocation and model design. - 3
Explore Advanced Techniques
Incorporate methods like Search Against Verifiers (SAV) and Diverse Verifier Tree Search (DVTS) to enhance output accuracy.
By embracing dynamic TTC and informed scaling, AI engineers can develop models that are both powerful and efficient.