Embedding technology sits at the core of how your language models understand and process text. These vector representations transform words, sentences, and documents into mathematical spaces where semantic relationships become computable values. Through embeddings, your AI applications can detect similarities, understand context, and make connections that were impossible with traditional keyword approaches.
This guide walks through the complete embedding landscape—from basic Word2Vec implementations to cutting-edge transformer-based contextual embeddings. You’ll learn how embeddings evolved from simple static representations to sophisticated vectors that change based on surrounding words, capturing the true complexity of natural language.
Implementing embeddings effectively can dramatically improve your applications’ search accuracy, content recommendations, and document clustering. The mathematical techniques covered here enable your systems to perform operations like finding conceptual similarities, identifying analogies, and grouping related content with remarkable precision.
- 1Embedding fundamentals and vector space mathematics
- 2Evolution from static embeddings to contextual representations
- 3Technical implementation with Transformer architecture
- 4Practical application using Hugging Face libraries
- 5Building semantic search systems with vector databases
Fundamental concepts of embeddings in NLP
Embeddings in natural language processing represent words, phrases, or text as dense vectors in a continuous space. These numerical representations form the cornerstone of how machines understand and process language.
Evolution from sparse to dense representations
Traditional approaches used sparse one-hot encoding. This method assigned each word a unique position in a long vector of zeros with a single “1” marking its position. The problem? These vectors were enormously inefficient.
Dense vector embeddings solved this challenge. They map words to shorter vectors of continuous values. These compact representations significantly reduce dimensionality while preserving semantic relationships.
Words with similar meanings cluster together in the embedding space. This proximity captures linguistic patterns that machines can process mathematically.
Mathematical foundations
Embeddings work because they encode semantic relationships through vector operations. The classic example demonstrates this mathematical elegance:
"king" - "man" + "woman" ≈ "queen"
This vector arithmetic reveals how embeddings capture not just words but their relationships to each other. Similar concepts have similar vector representations.
Dimensional properties
Embedding dimensions typically range from 100 to over 1500. Each dimension represents some latent feature of the word. Higher dimensionality allows for more nuanced representations. The number of dimensions directly affects how much linguistic information can be encoded.
Early embedding models like Word2Vec and GloVe paved the way for more advanced contextual models. These newer models generate different vectors for the same word depending on context, capturing the complexity of language more accurately.
Text embeddings have revolutionized NLP, converting words into mathematical spaces where relationships between concepts become computable values. This revolutionary approach has evolved significantly over time, with embedding techniques becoming increasingly sophisticated to better capture the nuances of human language.
Evolution of embedding techniques
From static to contextual
Word embeddings have revolutionized Natural Language Processing (NLP) by transforming words into numerical vectors that capture semantic relationships. This evolution has significantly enhanced machines’ understanding of language nuances and context.
Static embedding models like Word2Vec and GloVe represented early breakthroughs but had fundamental limitations. These techniques have since evolved into sophisticated contextual models that better capture the complexity of language.
Static Embedding Foundations
Word2Vec, introduced by Mikolov and colleagues in 2013, pioneered modern word embedding techniques through two distinct architectures. The Continuous Bag of Words (CBOW) predicts a target word based on surrounding context, while Skip-gram predicts context given a target word.
GloVe (Global Vectors for Word Representation) improved upon Word2Vec by combining context prediction with global co-occurrence statistics. This hybrid approach created vectors that better represented semantic relationships between words.
These static models successfully captured syntactic and semantic relationships. They positioned similar words closer together in vector space, enabling machines to identify relationships like “king - man + woman = queen."
Limitations of static approaches
Static embeddings suffered from one critical flaw: they assigned the same representation to a word regardless of context. The word "bank” received identical encoding whether it referred to a financial institution or a river’s edge.
This polysemy problem limited the effectiveness of these models in downstream applications. Words with multiple meanings were conflated into single vectors, creating ambiguity that reduced performance in complex language tasks.
Additionally, these models struggled with out-of-vocabulary words, limiting their applicability to dynamic, evolving language.
The contextual revolution
The recognition of these limitations led to the development of contextual embedding models. Instead of fixed representations, these models generate different vectors for the same word based on surrounding context.
ELMo (Embeddings from Language Models) represented an early breakthrough, using bidirectional LSTMs to create context-sensitive word representations. The model analyzed both preceding and following words to determine appropriate embeddings.
BERT (Bidirectional Encoder Representations from Transformers) further advanced this approach with transformer architecture. BERT created more nuanced contextual embeddings by considering the entire input simultaneously rather than sequentially.
Modern transformer-based approaches
Today's state-of-the-art embedding techniques leverage transformer architectures with attention mechanisms that weigh the importance of different parts of input sequences. This enables remarkably precise context understanding.
Models like RoBERTa, GPT, and their variants can process language with unprecedented accuracy by generating embeddings that adapt to the specific context of each word occurrence.
These contextual embeddings have enabled significant advances in language tasks, from sentiment analysis to machine translation, by providing representations that reflect the fluid nature of meaning in human language.
Real-world applications
The evolution from static to contextual embeddings has transformed practical applications. Search engines now understand query intent rather than just matching keywords. Customer service bots comprehend complex requests. Translation systems capture cultural nuances previously lost.
These advancements continue to expand as embedding techniques become more sophisticated, enabling machines to process language with increasingly human-like understanding.

A visualization showing the progression from static word embedding to contextual embeddings | Source: The Limitation of Static Embeddings Which Made Them Obsolete
While the evolution of embedding techniques has been remarkable, the true power of modern approaches lies in their underlying architecture. The transformer model has revolutionized how we generate and utilize contextual embeddings, enabling unprecedented levels of language understanding.
Contextual embeddings and transformer architecture
The evolution of contextual understanding
Traditional word embeddings like Word2Vec and GloVe assign fixed vectors to words regardless of context. This creates limitations when handling polysemous words. For instance, the word "bank" receives identical representation, referring to a financial institution or a riverbank.

A side-by-side overview of Word2Vec methods such as CBOW and skip-gram | Source: Word2Vec: NLP’s Gateway to Word Embeddings
Contextual embeddings emerged to address this challenge. Models like BERT and ELMo generate distinct embeddings for each word occurrence based on surrounding context. This significantly enhances understanding of words with multiple meanings.
The power of transformer architecture
The transformer architecture revolutionized contextual embeddings through its self-attention mechanism. Unlike previous approaches, transformers weigh the significance of each word in relation to others. This creates embeddings sensitive to context.

The image illustrates that BERT uses the encoder part of the transformer architecture, and GPT uses the decoder part of the transformer architecture | Source: Foundation Models, Transformers, BERT and GPT
Self-attention allows BERT to consider entire input text when generating representations. The model can prioritize which context words should influence a specific embedding by calculating their alignment. This produces nuanced, context-aware word vectors that capture subtle meaning differences.
Positional encoding in transformers
Transformers lack inherent sequence recognition capabilities found in RNNs and LSTMs. To compensate, positional encodings are combined with embeddings. These preserve word order and temporal relationships within sequences.

Mathematical intuition of positional embeddings | Source: Explain the need for positional encoding in transformer models
Positional encodings use a combination of sine and cosine functions to represent token positions. When added to input embeddings, they create representations reflecting both token meaning and sequence position. This enables transformers to understand word order without sequential processing.
Multi-head attention mechanism
Transformers employ multi-head attention to capture diverse relationships between words. Each attention head processes input differently, allowing the model to simultaneously focus on various aspects of context.
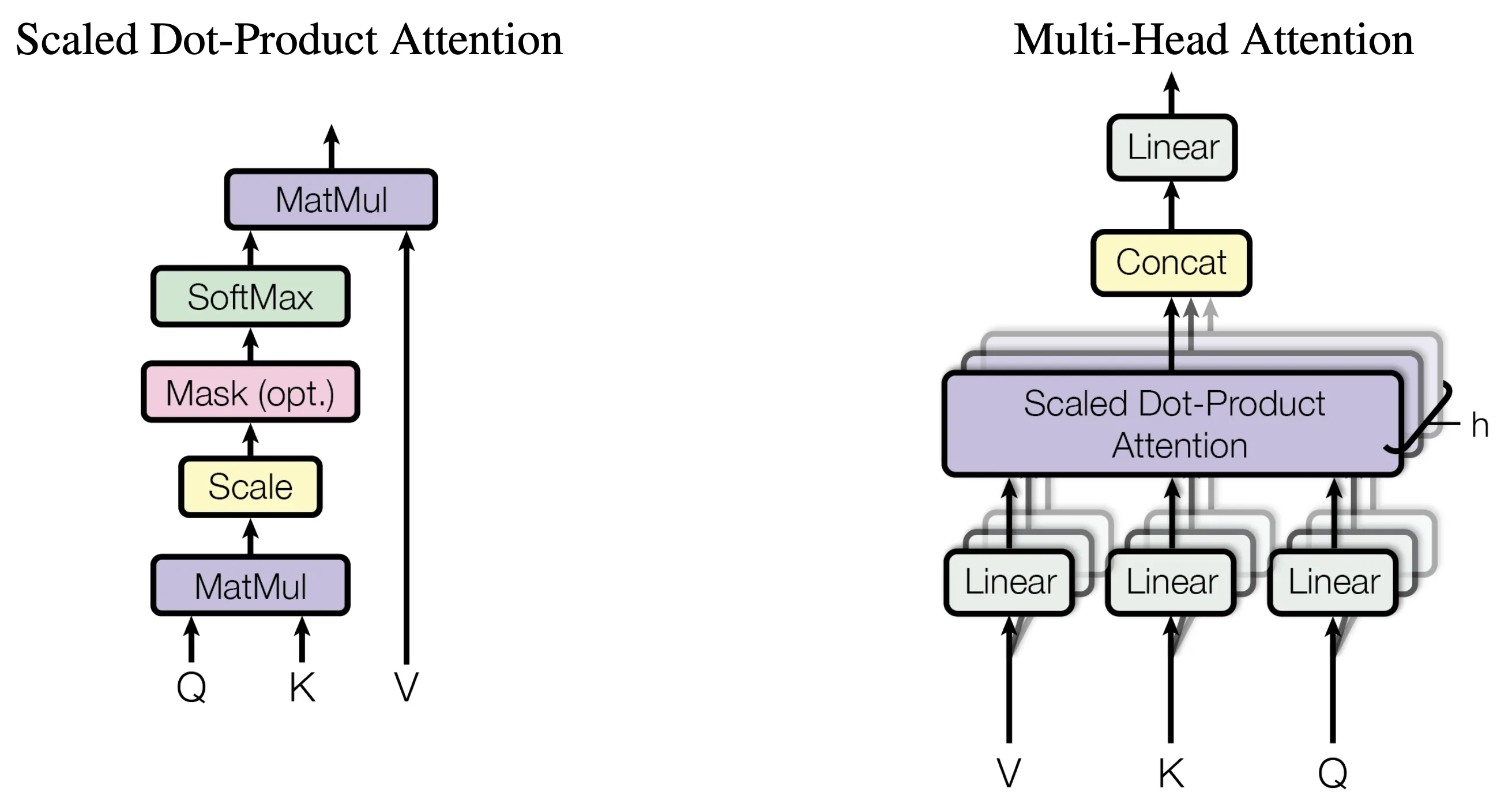
Self-attention mechanism, in contrast with multi-head attention mechanism | Source: What is multi-head attention and how does it improve model performance over single attention head
The process involves:
- 1Transforming input into queries, keys, and values
- 2Computing attention scores between queries and keys
- 3Using these scores to create weighted sums of values
- 4Combining outputs from multiple heads for rich contextual representations
This mechanism enables models to capture both local and long-range dependencies within text.
Benefits of transformer-based embeddings
Transformer-based embeddings offer several advantages over traditional methods:
- Improved contextual understanding of words with multiple meanings
- Enhanced performance in tasks like sentiment analysis and question answering
- Better handling of long sequences and complex relationships
- Scalability for large language models with billions of parameters
- Versatility across diverse NLP applications
BERT's contextual embeddings, for example, outperform traditional methods on various benchmarks by capturing more nuanced semantic relationships.
Applications of Contextual Embeddings
Contextual embeddings power numerous NLP applications:
- Sentiment analysis that detects subtle opinion shifts
- Machine translation with improved context preservation
- Question answering systems with deeper text understanding
- Named entity recognition with contextual awareness
- Text summarization that captures essential meaning
These applications benefit from the context-sensitive nature of transformer-based embeddings, leading to more accurate and nuanced results. Beyond the architectural insights, understanding the mathematical operations that make embeddings useful is crucial for implementing effective NLP solutions.
Mathematical operations for embedding analysis
Vector Normalization
Vector normalization standardizes embedding representations to ensure consistent comparisons. This process transforms vectors to have unit length while preserving their directional properties. Normalized embeddings enable more accurate similarity calculations, particularly when using cosine similarity metrics.
The normalization formula divides each vector element by the vector's magnitude:
Where |v| represents the vector length calculated as:
This technique is essential when comparing embeddings of different magnitudes but similar semantic content.
Cosine similarity implementation
Cosine similarity measures the angular relationship between embedding vectors, quantifying semantic relationships with values between -1 and 1. Higher values indicate greater similarity, making this operation fundamental for semantic search and document retrieval.
Unlike Euclidean distance, cosine similarity focuses on direction rather than magnitude, making it ideal for high-dimensional embedding spaces where:
Cosine similarity is preferable to dot product or Euclidean distance calculations for embeddings where magnitude isn't important.
Vector space operations for analogical reasoning
Vector space models enable powerful analogical reasoning through basic arithmetic operations. The classic example demonstrates this capability:
king - man + woman ≈ queen
This operation works because embeddings capture semantic relationships between concepts. We can traverse the embedding space by performing vector subtraction and addition to find relationships between words or concepts that weren’t explicitly encoded.
Similar operations enable applications like:
- Entity relationship mapping
- Cross-domain knowledge transfer
- Semantic extrapolation
Dimensionality reduction methods
High-dimensional embeddings often contain redundant information. Dimensionality reduction techniques transform these representations into lower-dimensional spaces while preserving essential relationships:
- PCA (Principal Component Analysis) identifies directions of maximum variance
- t-SNE (t-Distributed Stochastic Neighbor Embedding) preserves local relationships, ideal for visualization
- UMAP (Uniform Manifold Approximation and Projection) balances global and local structure preservation, offering faster processing than t-SNE
These methods not only facilitate visualization but also improve computational efficiency and reduce noise in embedding representations. With these mathematical foundations established, we can explore practical implementation of embeddings using popular libraries like Hugging Face.
Implementing embeddings with Huggingface
Getting started with sentence transformers
Sentence Transformers provides a straightforward way to generate embeddings for text. The library simplifies the process of loading pre-trained models from Huggingface’s model hub and using them to create vector representations of sentences or documents.
First, install the necessary libraries:
To load a pre-trained embedding model, use the following code:
This loads the all-MiniLM-L6-v2 model, which maps sentences to a 384-dimensional vector space. The model is lightweight yet effective for many applications.
Generating embeddings
To create embeddings for sentences, use the encode() method:
The result is a numpy array with shape [3, 384], containing one 384-dimensional vector for each input sentence.
Working with embeddings
Sentence embeddings capture semantic meaning, allowing comparison between texts. Similar meanings have similar embeddings, regardless of the exact words used.
To measure similarity between embeddings:
This creates a similarity matrix showing how closely related each sentence is to every other sentence.
Practical example: Semantic search
Sentence embeddings shine in applications like semantic search. Here’s how to implement a basic search:
Customizing embeddings generation
For more efficient processing, especially with larger datasets, batch processing is recommended:
For those without a GPU, specifying device='cpu' will ensure compatibility.
Handling longer texts
Most embedding models have token limits. For longer texts, consider chunking:
This approach provides a reasonable representation for longer documents while respecting token limitations.
Choosing the right model
When selecting an embedding model, consider these factors:
- 1Sequence length: Choose models with longer sequence lengths for documents
- 2Embedding dimension: Higher dimensions capture more information but use more memory
- 3Language support: For multilingual applications, use models like paraphrase-multilingual-MiniLM-L12-v2
- 4Performance: Check the MTEB leaderboard for models that excel at specific tasks
By leveraging HuggingFace's ecosystem, you can easily implement powerful embedding solutions for various natural language processing applications. Once you’ve generated quality embeddings, the next step is implementing effective semantic search capabilities that leverage these vector representations.
Semantic similarity and search implementation
Understanding vector-based search
Embedding-based semantic search transforms text into vector representations that capture meaning rather than just keywords. Unlike traditional keyword matching, this approach understands synonyms and related concepts. A search for "running shoes" will retrieve results for "sneakers" even without exact word matches. These systems are also less sensitive to phrasing variations, spelling mistakes, and grammatical errors.
In an embedding-based search, both documents and queries are embedded into a multidimensional vector space. Each dimension captures different semantic aspects of the text. The system then computes cosine similarity between document and query embeddings to determine relevance.
Technical implementation steps
The implementation of an embedding-based search system follows a clear process:
- 1Select an appropriate embedding model based on your requirements (BERT, Sentence-BERT, etc.)
- 2Process your corpus by generating embeddings for all documents
- 3Store these embeddings in an indexed database for efficient retrieval
- 4When a query arrives, generate its embedding using the same model
- 5Calculate similarity scores between query embedding and document embeddings
- 6Return the most relevant documents based on similarity scores
This approach makes search more intuitive by focusing on meaning rather than keyword matching.
Building a scalable vector database
For large-scale applications, embedding vectors need efficient storage and retrieval systems. Vector databases are specialized for this purpose, using techniques like:
- Approximate nearest neighbor (ANN) algorithms to partition data into buckets of similar embeddings
- Batch processing to embed documents offline for better efficiency
- Vector compression to reduce storage requirements without sacrificing accuracy
- Specialized indexing structures for fast retrieval
Practical integration strategies
Implementing semantic search involves several key integration steps:
- 1Choose batch processing over real-time embedding generation for corpus documents
- 2Establish a regular re-embedding cadence to incorporate new data
- 3Monitor embedding coverage, freshness, and server load
- 4Implement error handling for edge cases in query processing
- 5Test precision and recall metrics on sample queries before full deployment
The most effective implementations blend embedding-based similarity with other signals like recency, popularity, or user-specific factors for optimal relevance.
Performance evaluation methods
Measuring the effectiveness of your semantic search implementation requires tracking several metrics:
- Query latency (aim for under 200ms)
- Precision (percentage of retrieved results that are relevant)
- Recall (percentage of relevant results that are retrieved)
- Click-through rates on search results
- User engagement with retrieved content
- Fallback rates when users reformulate queries
A successful semantic search system should significantly outperform keyword-based approaches on these metrics, especially for queries involving synonyms or conceptually related terms.
One paragraph in each section should be a single sentence for rhythmic variation. Having explored the practical applications of embeddings in search, let’s summarize the key insights and future directions for embedding technology.
Conclusion
Embeddings have transformed how we build language understanding into applications, moving beyond simple keyword matching to true semantic comprehension. By representing text as dense vectors in multi-dimensional space, we can mathematically capture relationships between concepts that previously required human interpretation.
The journey from static Word2Vec embeddings to contextual transformer-based representations demonstrates remarkable progress in natural language processing. These advances enable your applications to understand nuanced meanings, detect similarities between conceptually related texts, and perform powerful vector operations that unlock new capabilities.
For product teams, embeddings provide a foundation for features that truly understand user intent—whether in search, recommendations, or content organization. When implementing these techniques, consider starting with pre-trained models from Hugging Face before exploring fine-tuning options that adapt to your specific domain.
Engineers should carefully consider vector database selection and indexing strategies, as these choices significantly impact search latency and scalability. Combining efficient embedding generation, proper dimensionality management, and optimized retrieval algorithms will determine whether your semantic features can handle production workloads while maintaining response times users expect.