
Large language models power innovation but often function as impenetrable black boxes. Understanding how these systems make decisions has become essential for product teams building trustworthy AI applications. This guide bridges the gap between theoretical research and practical implementation of interpretability techniques—helping you build better, more transparent LLM products.
We'll explore the critical distinction between interpretability (understanding how models work internally) and explainability (communicating why they make specific decisions). You'll learn both fundamental concepts and advanced techniques for peering inside complex neural networks, with practical approaches for implementing these methods in your development workflow.
These interpretability methods deliver concrete benefits: they help debug unexpected outputs, identify model biases, meet regulatory requirements, and build user trust. By implementing the frameworks described here, your team can create AI products that balance performance with the transparency increasingly demanded by users and regulators.
Key Topics Covered:
- 1The technical differences between interpretability and explainability
- 2Foundation concepts in transformer architecture and LLM interpretability
- 3Practical techniques: attention visualization, feature attribution, and circuit discovery
- 4Building an assessment framework for measuring transparency
TL;DR
Large language models often operate as black boxes. This article explains the difference between interpretability (understanding model internals) and explainability (communicating decisions to humans). It covers transformer architecture fundamentals, practical techniques like attention visualization and feature attribution, and advanced approaches like mechanistic interpretability. The article provides a framework for assessment and implementation strategies for product teams. By integrating these methods, teams can build more transparent AI systems that balance performance with trustworthiness, which helps debug outputs, detect biases, meet regulations, and build user confidence.
Interpretability vs. Explainability
Interpretability and explainability are critical concepts in large language models that, while related, serve distinct purposes in making AI systems transparent and trustworthy. Understanding their differences is essential for product teams designing LLM applications.
What is interpretability?
Interpretability focuses on understanding a model's internal workings and decision-making processes. It aims to make the inner mechanics of an AI system visible, particularly to technical stakeholders.
Interpretability techniques enable visibility into transformer attention mechanisms and internal model representations. These include:
- Attention visualization (mapping how models attend to input tokens)
- Mechanistic interpretability (reverse-engineering model components)
A truly interpretable model allows observers to understand exactly how inputs are processed and transformed into outputs. This level of transparency reveals what happens inside the "black box" of an LLM.
What is explainability?
Explainability, by contrast, concerns communicating model decisions to humans in understandable terms. While interpretability reveals how a model works, explainability focuses on why it made specific decisions.
Explainability methods include:
- Rule-based explanations
- Perturbation-based methods
- Counterfactual explanations
These approaches help stakeholders comprehend LLM outputs without requiring deep technical knowledge of the model itself.
Rather than exposing model internals, explainability provides post-hoc explanations of model behavior that humans can easily grasp. It bridges the gap between complex AI systems and human understanding.
Key differences in approach and application
The fundamental distinction lies in their methodologies and scope. Interpretability examines how inner workings clarify decision-making behavior. Explainability doesn't require understanding inner workings but instead focuses on explaining decisions after they're made.
Interpretability works best with simpler models. The transparency needed for true interpretability becomes increasingly difficult as models grow more complex.
Explainability, focused on specific scenarios rather than the entire model, often proves more practical for complex models like LLMs where internal behaviors are harder to understand.
Practical implications for product teams
Product teams can leverage these approaches differently based on their specific needs:
- 1Interpretability techniques help identify biases
- 2Improve outputs during development
- 3Meet regulatory requirements through cross-functional collaboration
When deciding which to prioritize, consider your product's use case and regulatory requirements. For high-risk applications in regulated industries, interpretability may be essential. For consumer applications, explainability might better serve user trust and adoption.
Teams should establish interpretability metrics aligned with product goals. These create feedback loops where insights inform product iterations.
The trade-off between performance and transparency
Some interpretability techniques impact LLM performance, leading to a trade-off between accuracy and transparency. Finding the right balance is essential and requires continuous research to optimize both aspects.
For product teams, this means carefully evaluating where transparency is most needed versus where performance takes priority. An interpretability assessment framework can help evaluate these needs across different product components and user interactions.
As a single-sentence takeaway: Interpretability reveals how models work, while explainability communicates why they make specific decisions.
With this foundation in interpretability and explainability established, we can now examine the technical underpinnings that make these approaches possible.
Technical foundations of LLM interpretability
To effectively apply interpretability methods to large language models, we must first understand the technical architecture that makes these analyses possible.
Transformer architecture enables interpretability research
The study of how large language models (LLMs) make decisions requires understanding their core architecture:
- Attention mechanisms allow models to focus on specific words during processing
- Visualizing attention weights reveals which input parts are most relevant for predictions
- Residual connections create pathways for information to flow unimpeded through the network

This diagram illustrates two key attention components that form the foundation of transformer models used in LLMs. On the left, Scaled Dot-Product Attention shows the sequential processing of query (Q) and key (K) matrices through matrix multiplication, scaling, optional masking, and softmax normalization, ultimately producing weighted attention over values (V). On the right, Multi-Head Attention demonstrates how multiple scaled dot-product attention operations run in parallel (h heads), allowing the model to simultaneously attend to information from different representation subspaces. These attention mechanisms are crucial for interpretability research as they reveal how models prioritize different parts of input sequences and form the basis for techniques like attention visualization that help researchers understand model decision-making processes. | Source: Attention Is All You Need
These architectural elements make it easier to trace how representations evolve throughout the model.
Scaling laws introduce unique challenges
The massive scale of modern foundation models poses distinct interpretability challenges:
- Emergent capabilities appear unpredictably as models grow larger
- These behaviors cannot be explained through simple extrapolation of smaller model performance
- Interpretability researchers must develop new techniques that account for this non-linear relationship between model size and capabilities
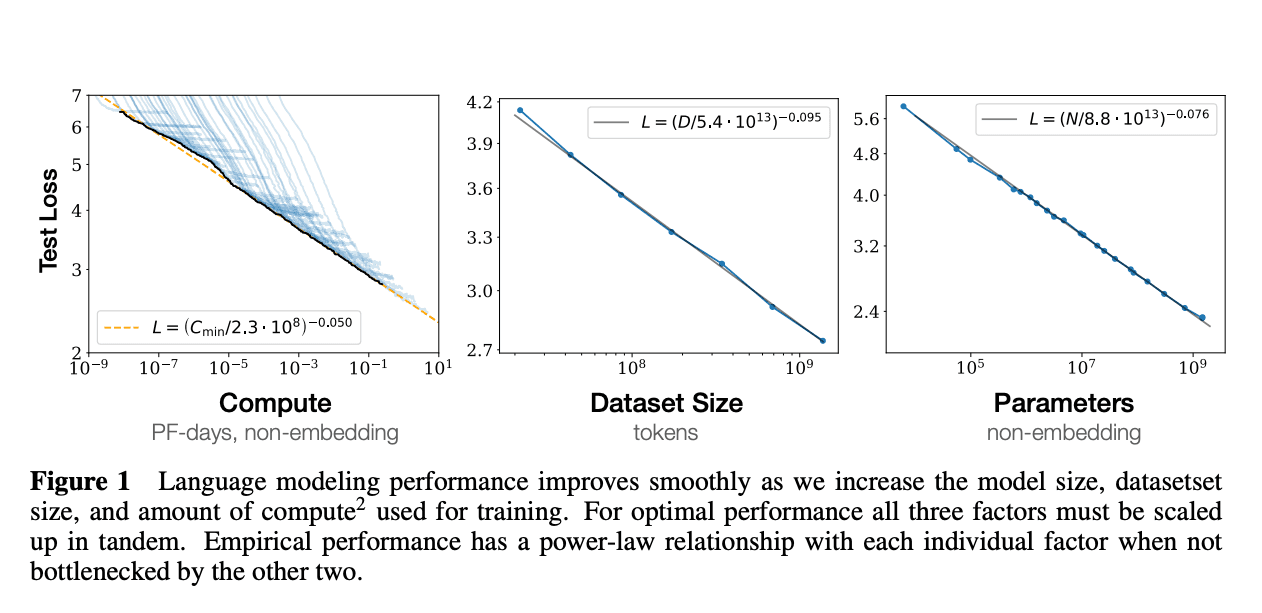
This figure shows power-law relationships in language model performance. Test loss decreases predictably with more compute (left), larger datasets (middle), and increased parameters (right). Each graph reveals mathematical patterns in model improvement. These scaling laws create interpretability challenges. Emergent capabilities appear at specific thresholds. They aren't visible in smaller models. Specialized techniques are needed. They help analyze how representations change across different scales of complexity. | Source: Scaling Laws for Neural Language Models
Traditional vs. LLM interpretability methods
Interpretability methods for traditional machine learning models often prove inadequate for LLMs. While feature attribution might work for logistic regression, LLMs require specialized approaches like mechanistic interpretability. This involves reverse-engineering specific circuits within the model that perform identifiable functions.
Architecture choices constrain interpretability approaches
Model architecture decisions significantly impact what interpretability methods can be applied:
- 1Polysemantic neurons - individual units represent multiple concepts simultaneously, complicating analysis
- 2Layer normalization - affects how information flows and which features are represented linearly
- 3Feed-forward networks - function as key-value memories that store and retrieve contextual information
Probing tasks reveal hidden representations
Probing tasks test what linguistic properties are captured in different model layers. By analyzing layer outputs, researchers can understand how information is processed hierarchically. This technique enables insights into how LLMs transform input data, helping interpret decisions made at each processing stage.
Transformer models intentionally create complexity through distributed representations, making full interpretability an ongoing research challenge that requires multiple complementary techniques working in concert.
Now that we understand the technical foundations, let's explore how these concepts translate into practical techniques that product teams can implement.
Practical interpretability techniques for product development
Moving from theory to application, this section explores the tangible methods product teams can use to gain insights into their LLM systems.
Understanding interpretability in LLM workflows
Interpretability techniques help product teams understand how large language models reason and make decisions. These techniques provide visibility into the inner workings of LLMs, allowing teams to:
- Debug unexpected outputs
- Improve model performance
- Create more transparent user experiences
Interpretability is essential for building trust and ensuring the responsible deployment of AI systems in production environments.
Interpretability approaches range from simpler visualization methods to sophisticated mechanistic techniques that reverse-engineer neural networks. Each approach offers unique insights that can inform product development decisions.
Attention visualization for debugging
Attention visualization maps how models focus on input tokens during processing. This technique reveals which parts of the input most strongly influence the model's output. For product teams, attention maps can quickly identify when models are focusing on irrelevant or misleading parts of prompts.
By visualizing attention patterns, developers can pinpoint exact failure points in complex workflows. For example, if a customer service AI consistently misunderstands certain types of queries, attention visualization might reveal the model is over-focusing on specific tokens while ignoring critical context.

This image displays attention heatmaps from LLaMA-2-7B-chat on various datasets (COPA, SST2, CQA, ARCE, BoolQ). The upper section shows full model attention patterns across datasets. The lower section breaks down layer-by-layer attention when processing SST2 samples. Brighter colors indicate stronger attention weights. Green boxes highlight attention sinks - areas where attention focuses unexpectedly. These visualizations help product teams debug model behavior by revealing how attention shifts across different layers and identifying potential issues. When models underperform, these maps can pinpoint where attention focuses incorrectly, enabling targeted improvements rather than relying on trial-and-error prompt adjustments. | Source: Unveiling and Harnessing Hidden Attention Sinks: Enhancing Large Language Models without Training through Attention Calibration
These visualizations serve as powerful debugging tools, especially when combined with user feedback data to correlate patterns of model failures.
Feature attribution methods
Feature attribution techniques like SHAP (Shapley Additive explanations) and Integrated Gradients quantify how each input feature contributes to model outputs. These methods help product teams understand which parts of inputs drive specific responses.
SHAP values, in particular, provide consistent and mathematically grounded attributions that explain individual predictions. By analyzing these values, teams can:
- Identify which parts of prompts have the biggest impact on responses
- Detect biases in how models process certain types of inputs
- Understand when models are relying on spurious correlations rather than causal relationships
Feature attribution helps bridge the gap between technical teams and product stakeholders by providing clear, quantifiable explanations for model behavior.
Measuring interpretability effectiveness
Evaluating the effectiveness of interpretability techniques requires both quantitative metrics and qualitative assessment.
Key metrics include:
- 1Faithfulness - how accurately the explanation reflects the model's actual reasoning
- 2Comprehensibility - how easily stakeholders can understand the explanations
- 3Actionability - how effectively the insights can guide model improvements
Product teams should establish interpretability benchmarks aligned with product goals and user needs. These benchmarks should reflect the specific transparency requirements of different product components and user interactions.
Regular evaluation helps teams track progress in making models more transparent and trustworthy over time.
Implementation considerations for startups
Resource-constrained startups face unique challenges when implementing interpretability tools. Rather than attempting comprehensive interpretability across all model components, startups should:
- 1Focus interpretability efforts on high-risk or customer-facing components first
- 2Integrate lightweight interpretability tools into existing development workflows
- 3Balance interpretability needs with performance considerations
Cross-functional collaboration is essential for effective implementation. Technical teams must work closely with product managers to determine which aspects of model behavior most need explanation and how insights should be presented to different stakeholders.
Startups should also consider the tradeoffs between model performance and interpretability. While some interpretability techniques may impact processing speed, the benefits of increased transparency and improved debugging capabilities often outweigh these costs.
Creating feedback loops with interpretability
The most effective implementation of interpretability techniques creates continuous feedback loops between model insights and product improvements. This requires:
- 1Establishing clear channels for sharing interpretability findings across teams
- 2Developing processes for converting interpretability insights into actionable model improvements
- 3Creating documentation that tracks how interpretability findings influence product decisions
When implemented effectively, these feedback loops accelerate product iteration cycles by pinpointing exactly where and how models need to be improved. Interpretability becomes not just a technical tool, but a cornerstone of the product development process.
With these practical techniques in mind, let's now examine more advanced methods that provide even deeper insights into model behavior.
Mechanistic interpretability: Advanced techniques for model understanding
For teams seeking to go beyond basic interpretability approaches, mechanistic interpretability offers a deeper level of insight into how LLMs process information and make decisions.
Mechanistic interpretability has emerged as a cutting-edge approach to demystifying the inner workings of large language models. This field focuses on reverse-engineering neural networks to understand exactly how they process information and generate outputs.
Sparse autoencoders for hidden representations
Sparse autoencoders (SAEs) have become a powerful tool for interpreting transformer models. These techniques decompose complex, polysemantic activations into more interpretable monosemantic features.
Recent advancements:
- Anthropic demonstrated how SAEs can extract meaningful features from models like Claude
- Researchers can identify specific behaviors by analyzing activation patterns rather than individual neurons
- SAEs provide more interpretable representations of what models "see" internally

This image shows sparse autoencoder results from Claude 3 Sonnet. Researchers extracted millions of monosemantic features from the model. The visual highlights a specific feature (#1M/847723) that detects "sycophantic praise" patterns. Key phrases that activate this feature are highlighted in orange, including "generous and gracious man," "oh, master," and "great lord." The right side shows how this feature influences model completions, generating excessively flattering responses. This demonstrates how SAEs make internal model behaviors visible and interpretable, allowing researchers to identify specific triggers for unwanted outputs and potentially steer model behavior through targeted interventions. | Source: Scaling Monosemanticity: Extracting Interpretable Features from Claude 3 Sonnet
Causal tracing and activation patching
Activation patching and causal tracing provide methods to isolate and understand specific behaviors in LLMs:
- 1Intervene on internal model activations
- 2Observe how outputs change
- 3Determine which components are responsible for particular capabilities
These techniques create a causal map of how information flows through the model, revealing dependencies between different parts of the architecture.
Circuit discovery applications
Circuit discovery techniques identify groups of neurons and attention heads that work together to perform specific functions. This approach has practical applications for product teams:
- Enabling targeted debugging and model improvement
- Pinpointing components responsible for unexpected outputs
- Allowing for more precise intervention than prompt-based fixes alone
Cost-benefit considerations
Implementing advanced mechanistic interpretability techniques requires significant resources. For startups with limited budgets, the investment must be weighed against potential benefits. While full model interpretability may be out of reach, targeted analysis of critical behaviors can provide valuable insights. Teams should prioritize understanding components most relevant to their product's core functionality and focus interpretability efforts where they deliver the most value.
The field continues to evolve rapidly, with new methods promising more efficient and scalable approaches to understanding model internals. As these techniques mature, they will become increasingly accessible to organizations beyond research labs.
After exploring the technical approaches to interpretability, we need a structured way to evaluate their effectiveness in real-world applications.
Building an interpretability assessment framework
To systematically evaluate and improve interpretability efforts, product teams need a comprehensive framework that guides implementation and measures effectiveness.
Developing an effective interpretability assessment framework is essential for understanding and improving large language model (LLM) behavior. This framework serves as a structured approach to evaluate how well we can understand model decision-making processes.
Establishing quantitative metrics
Interpretability requires measurable standards. Define clear metrics that align with product goals, from simple attention visualization scores to complex mechanistic interpretability measurements. These metrics should capture both technical depth and user comprehension.
Sample metrics to track:
- Feature attribution accuracy to measure how well interpretations identify influential input tokens
- Consistency between interpretability findings and model outputs
- User comprehension scores for different explanation types
- Time required to diagnose specific model behaviors
Your metrics must balance technical rigor with practical utility. A technically sound interpretation that users cannot understand fails to serve its purpose.
Creating cross-functional collaboration
Interpretability assessment cannot function in isolation. Form teams with:
- Technical experts who understand model architecture
- Product stakeholders who know how interpretations will be used in real applications
Collaboration structure:
- 1Technical staff provide insights into attention mechanisms and model components
- 2Product teams ensure interpretations address practical concerns like bias detection
- 3Legal/compliance ensures interpretability meets regulatory requirements
- 4UX researchers evaluate how effectively explanations are understood by users
This collaboration creates a feedback loop where interpretability insights directly inform product improvements. When technical and product perspectives align, interpretability becomes a powerful tool for product enhancement.
Implementing continuous monitoring
Interpretability isn't a one-time assessment. Build systems that monitor model interpretability in production environments:
- 1Track how interpretations evolve as models process new inputs
- 2Monitor changes in interpretability metrics after model updates
- 3Establish alerts for unexpected shifts that might indicate biases
- 4Document interpretability patterns across different user segments
This continuous monitoring helps maintain trust in model outputs over time.
Balancing depth with usability
A common challenge in interpretability assessment is striking the right balance between technical depth and practical usability:
Develop tiered interpretability outputs tailored to different stakeholders. Technical teams can access in-depth mechanistic interpretations, while product managers receive simplified visualizations that highlight key decision factors.
Remember that the most technically accurate interpretation isn't always the most useful. Sometimes a simpler explanation better serves user needs.
Integration with existing pipelines
To be effective, interpretability assessment must integrate with your existing ML evaluation workflows:
- 1Add interpretability metrics to your standard assessment suite
- 2Evaluate interpretability alongside accuracy and performance
- 3Create decision frameworks that balance performance and transparency
- 4Document interpretability findings in the same systems as other model metrics
This integration ensures interpretability becomes a core consideration rather than an afterthought. It also helps teams understand tradeoffs between model performance and interpretability.
When evaluating model improvements, consider both performance gains and interpretability impacts. Sometimes a slightly less accurate but more interpretable model provides more overall value.
Conclusion
Interpretability represents a critical capability for product teams working with LLMs. By implementing the techniques outlined in this guide—from basic attention visualization to advanced mechanistic approaches—you gain visibility into model behavior that directly improves product quality and user trust.
For technical implementation, prioritize interpretability methods based on your specific use case:
- 1Start with lightweight visualization tools that integrate into existing workflows
- 2Advance to more sophisticated techniques like sparse autoencoders and circuit discovery
- 3Create tiered outputs that serve different stakeholders:
Product managers should:
- Incorporate interpretability metrics into evaluation frameworks
- Use insights to identify high-value model improvements
- Determine where transparency is most critical for user adoption
- Build feedback loops connecting interpretability findings to product iterations
For startup leadership, interpretability offers strategic advantages:
- Mitigates regulatory risks
- Builds differentiation in increasingly crowded AI markets
- Creates a foundation for responsible scaling
- Positions your company for sustainable growth as AI governance requirements increase
By investing in transparency now, you create both technical and business advantages that will become increasingly valuable as AI applications continue to expand across industries.