
What is Few-shot Prompting?
Few-shot prompting is an in-context learning technique that provides the LLM with examples of the desired task pattern without changing model parameters. This method leverages the model's ability to identify patterns from 1-5 input-output examples and apply them to new inputs.

Overview of LLM meta learning process. This process makes the model excel in few-shot learning. | Source: Large Language Models are Zero-Shot Reasoners
Few-shot prompting functions by demonstrating the expected input-output relationship through examples. The model recognizes patterns from these examples and uses this understanding to complete similar tasks with new inputs. This happens entirely at inference time without updating model weights. This elegant approach allows models to adapt quickly without the computational overhead of traditional training methods.
Why Use Few-shot Prompting Over Other Reasoning Prompts?
Few-shot prompting represents a powerful technique for extracting specific behaviors from LLMs without modifying their underlying parameters. By providing 1-5 carefully selected examples within your prompts, you can dramatically improve formatting control, reduce hallucinations, and optimize costs—all crucial capabilities when building production AI features that perform consistently.
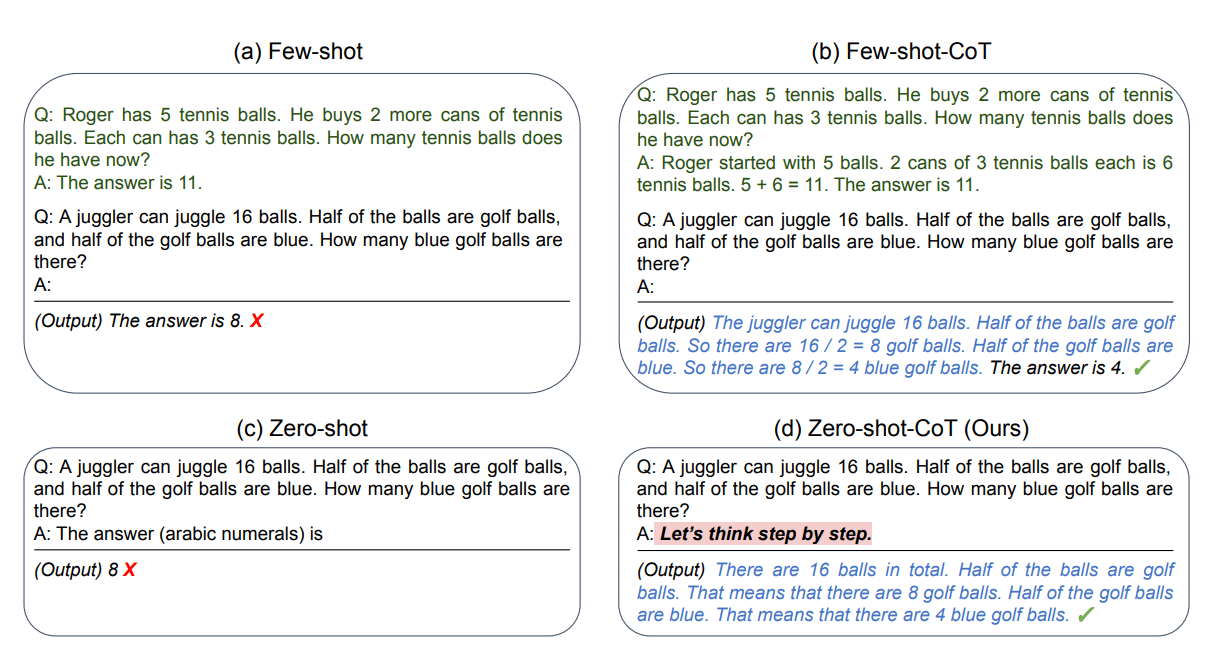
Comparison of Few-shot prompt and Few-shot-CoT for better results | Source: Large Language Models are Zero-Shot Reasoners
I have highlighted a couple of benefits that make few-shot prompting powerful over other techniques.
Core benefit 1
Benefit in terms of cost efficiency:
- 40-60% cost reduction versus fine-tuning approaches
- Drops per-request costs from 0.06 to 0.03 cents (50% decrease)
Core benefit 2
When it comes to speed to market:
- Accelerates implementation with immediate deployment
- Eliminates training cycles and complex architecture setup
- Enables rapid iteration on AI-powered features
When to avoid it?
- Not optimal for tasks requiring extensive reasoning beyond examples provided
- Less effective when examples cannot adequately represent the full task complexity
- Consider alternatives when working with highly specialized domain knowledge
- May underperform when consistency across varied inputs is critical
How Few-shot Works — Step by Step
Few-shot prompting effectiveness stems from how LLMs process patterns in the provided examples. Models apply a form of Bayesian inference, using the examples to narrow down the probability distribution of potential responses. This process activates the model's pattern recognition capabilities, enabling it to produce responses that follow the demonstrated format and reasoning.
Research shows that 3-5 examples typically provide optimal performance gains across different model architectures. Performance improvements plateau after 5-8 examples, with diminishing returns for additional examples. The selection and arrangement of examples significantly impact results, with biases like Majority Label Bias and Recency Bias affecting outcomes.
The examples you choose significantly impact performance. Select examples that:
- 1Represent diverse cases within your target domain
- 2Match the format and structure of your target outputs
- 3Include edge cases that demonstrate boundary conditions
- 4Maintain consistent formatting across all examples
Prompt Templates
In the table below, I have shown how product leaders can use few-shot learning for five various tasks.
Choosing the right LLM for Few-shot prompting in 2025
Pros, Cons & Common Pitfalls
Pros
- Enables smaller models to match performance of models up to 14× larger
- Achieves dramatic cost efficiency (up to 98.5% reduction from 3.2 cent to 0.05 cent per request)
- Processes requests up to 78% faster than larger models
- Reduces hallucinations by up to 32% compared to zero-shot approaches
- Cuts prompt token costs by 70% while maintaining quality with targeted examples
- Optimizes token usage through batch prompting
- Provides flexibility without model retraining
Cons
- Requires careful example curation and selection
- Increases token usage compared to zero-shot prompting
- May introduce recency bias (favoring patterns in most recent examples)
- Performance varies significantly by task complexity and model size
- Demands more context window space for examples
Common Pitfalls
- Selecting poor or unrepresentative examples
- Using too many examples (diminishing returns after 5-8 examples)
- Failing to test different example orderings
- Not establishing proper baseline metrics for comparison
- Overlooking the impact of example diversity
- Neglecting systematic evaluation protocols
- Assuming consistent performance across different model architectures
- Not documenting successful patterns for future implementations
Empirical Performance
In this section, we will examine a couple of comparison graphs of three prompting techniques and a table that compares the various LLMs in the MMLU dataset.
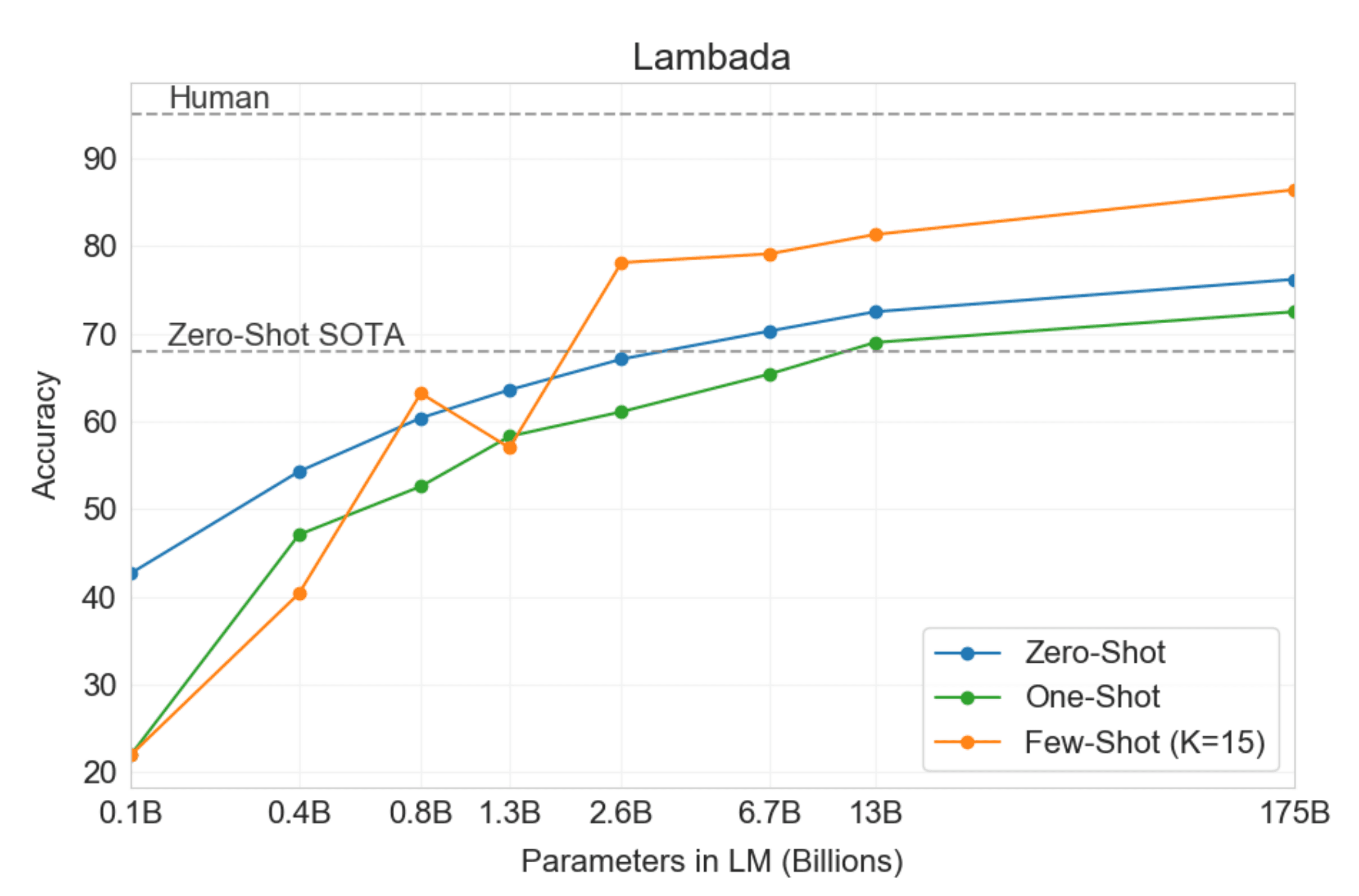
As the model scales up, Few-shot prompting tends to perform better than Zero-shot and One-shot prompting | Source: Large Language Models are Zero-Shot Reasoners
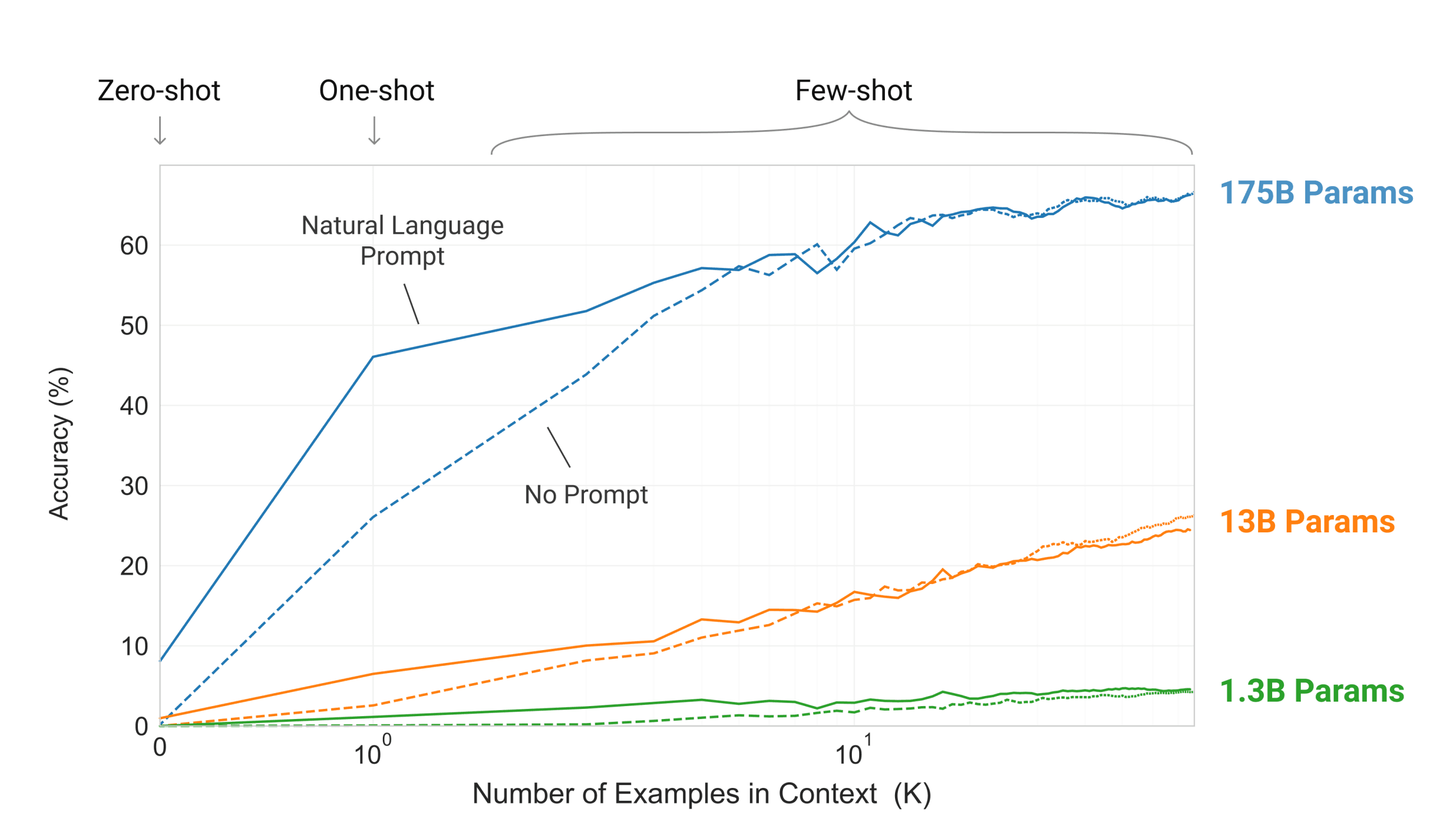
The more context or examples LLMs receives as context the better they performs | Source: Large Language Models are Zero-Shot Reasoners
This table illustrates the performance of various LLMs on a standard test known as MMLU. The test measures how well these models can answer questions across many subjects.
Each model was tested in two ways:
- 1Zero-Shot: The model answers questions without any examples to learn from
- 2Five-Shot: The model gets 5 examples before answering similar questions
The key findings are:
- All models improve by about 4 percentage points when given examples
- GPT-4.5 performs the best overall (92% with examples)
- Even smaller models like o4-mini show significant improvement when given examples
- Llama-4 Maverick shows the biggest improvement (+5 points) when given examples
- Higher-end models (like GPT-4.5) still outperform budget models (like o4-mini) by a wide margin
This demonstrates that providing examples enhances the performance of all AI models, regardless of their size or capabilities.
Using Adaline for Few-shot Prompt Engineering
In this section, I will show you how to use Adaline.ai to design your prompts.
First, you will need to select the model. For this example, I will choose o4-mini as it is a fast reasoning model. But feel free to use any model that fits your needs. Adaline.ai provides a wide variety of models from OpenAI, Anthropic, Gemini, Deepseek, Llama, etc.

Second, once the model is selected, we can then define the system and user prompts.

The system prompt defines the role and purpose of the LLM for a particular task. In this case, “You are a helpful assistant. Follow the examples exactly. When given a new task, look at the few examples and then answer the task step by step.”
The user prompt defines the task at hand – what it needs to do when provided with a piece of information. Using this structured approach will yield better results and greater robustness.

Third, once the prompts are ready, just hit run in the playground.

Adaline.ai will execute your prompts using the selected LLM and provide you with the answer.

Now, if you want to fine-tune or polish the existing output, then you just click on “Add message.” “Add message” will allow you to add a follow-up prompt like a chatbot to polish your prompt.

Once you add a follow-up prompt, click on “Run.” It will continue the conversation from the previous output. Look at the example below.

I added a new user message, “Please break down the three points,” and executed the prompt. Adaline.ai continued the conversation using o4-mini and provided the output.
Adaline.ai provides a one-stop solution to quickly iterate on your prompts in a collaborative playground. It supports all the major providers, variables, automatic versioning, and more.
Get started with Adaline.ai.