What is Self-Consistency Prompting?
Self-consistency prompting is a decoding strategy that enhances the reasoning capabilities of Large Language Models (LLMs) by generating multiple reasoning paths and selecting the most consistent answer. This approach builds upon Chain-of-Thought (CoT) prompting to improve performance on complex reasoning tasks.
Self-consistency operates through three essential mechanisms:
- 1
Diverse path generation
Instead of using greedy decoding to produce a single reasoning process, self-consistency samples multiple diverse reasoning paths for the same prompt. This is achieved by setting a non-zero temperature during generation. - 2
Multiple independent solutions
The LLM attempts to solve the same problem multiple times, potentially discovering different approaches to reach an answer. - 3
Majority voting
After collecting all final answers from these different reasoning paths, the system selects the most frequently occurring answer as the correct solution.
Unlike greedy Chain-of-Though, which produces only one reasoning trajectory, self-consistency explores multiple reasoning angles to arrive at a more reliable answer.
By generating various reasoning paths, it becomes more robust to individual reasoning errors that might occur in any single attempt.
The approach leverages stochastic decoding rather than deterministic (greedy) decoding, introducing beneficial randomness into the solving process.
Why Use Self-Consistency Prompting Over Other Reasoning Prompts?
When building AI products that require complex reasoning, accuracy matters. Self-consistency prompting offers a powerful technique to significantly improve your LLM's reasoning capabilities without any fine-tuning or additional training. This approach generates multiple reasoning paths for the same question and determines the most frequent answer, effectively reducing errors that might occur in any single attempt.
Core benefit 1: Boosting CoT prompting performance
Self-consistency boosts CoT prompting performance by substantial margins across various benchmarks:
- 17.9% accuracy improvement on GSM8K
- 11.0% higher performance on SVAMP arithmetic reasoning
- 12.2% better results on AQuA benchmark
- 6.4% improvement on StrategyQA commonsense reasoning
- 3.9% gain on ARC-challenge benchmark
On arithmetic tasks specifically, Cohere Command with self-consistency reached 68% accuracy compared to 51.7% with greedy CoT—a remarkable 16.3 percentage point difference.
Core benefit 2: Generating diverse reasoning approaches
Self-consistency works by generating diverse reasoning approaches to the same problem, effectively mitigating errors that might occur in any single reasoning attempt.
The technique samples multiple paths instead of relying on a single chain of thought. Tests show that increasing the number of sampled reasoning paths improves performance up to a plateau around 40 paths, though most gains emerge with just 5-10 samples.
Consistency analysis shows a strong correlation between how often the model arrives at the same answer and the likelihood of that answer being correct. This relationship enables developers to use consistency as a proxy for confidence in the model's response.
When to avoid it?
Self-consistency introduces significant latency challenges for real-time applications. The sequential generation of multiple reasoning paths extends response time, making it unsuitable for interactive systems requiring immediate feedback. While parallel processing can mitigate some delays, it increases infrastructure requirements and costs.
The approach particularly excels at tasks with definitive answers such as math problems and classification scenarios. It's less effective for tasks with non-uniform outputs like summarization.
How Self-Consistency Works — Step by Step
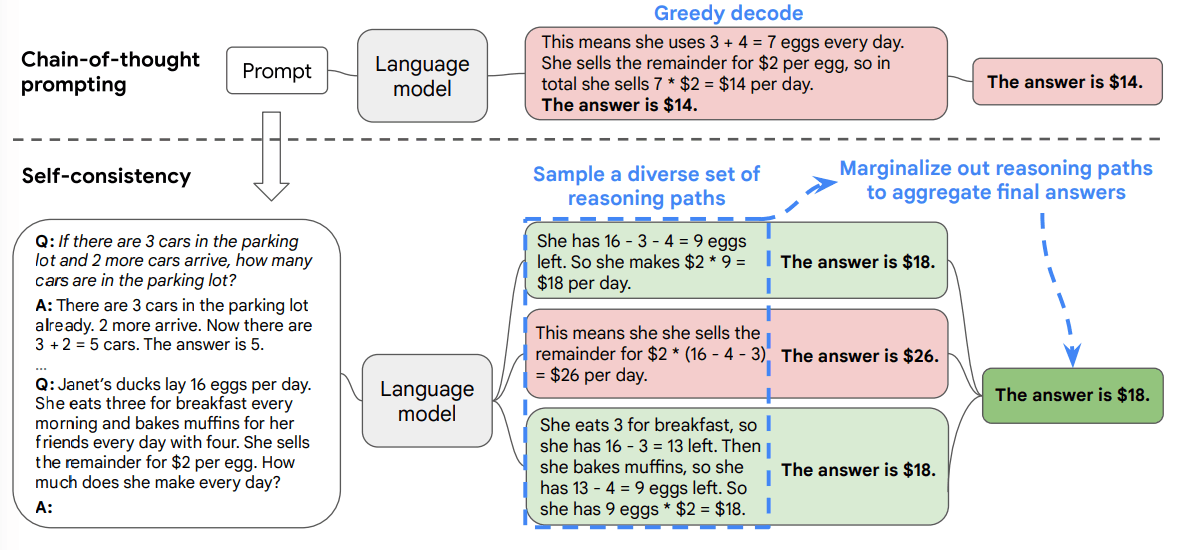
Overview of Self-consistency prompting via three sequential steps | Source: Self-Consistency Improves Chain of Thought Reasoning in Language Models
To implement self-consistency prompting:
- 1Start with a prompt that elicits step-by-step reasoning, typically using Chain-of-Thought approaches
- 2Run this prompt multiple times (often 5-30 iterations) with temperature settings above 0
- 3Extract the final answer from each generated reasoning path
- 4Count the frequency of each answer
- 5Select the most common answer as your final result
The temperature setting during sampling plays a crucial role in self-consistency prompting performance. Higher temperature values (0.5-1.0) encourage more diverse reasoning paths, while maintaining enough coherence for accurate solutions.
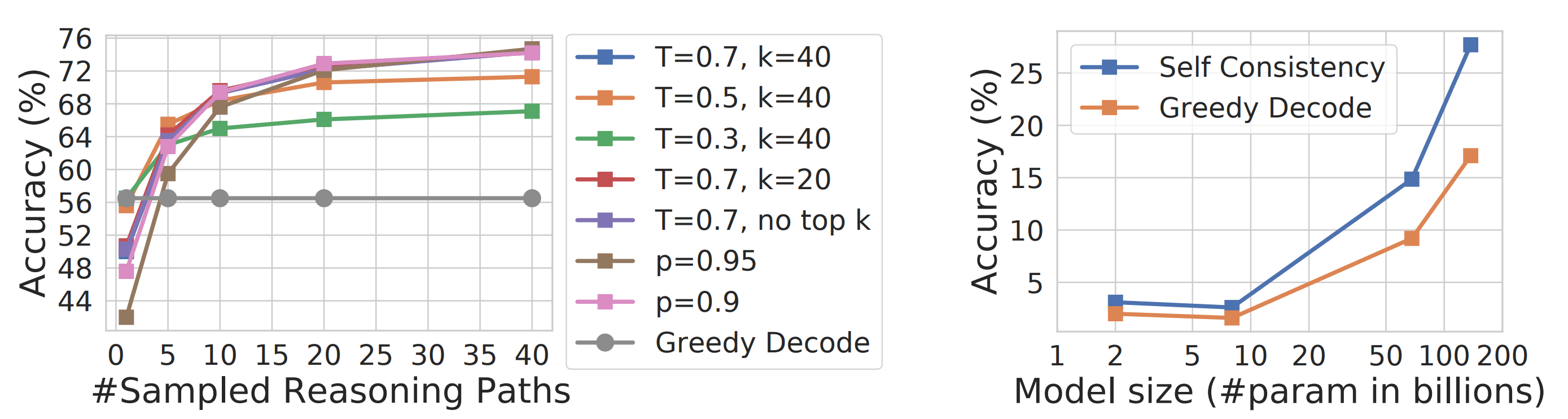
Experiments show that a higher temperature setting, somewhere around 0.7, yields more accuracy | Source: Self-Consistency Improves Chain of Thought Reasoning in Language Models
Experimental results across multiple temperature values (0.5, 0.7, and 1.0) show that self-consistency remains robust to these variations. Even at a moderate temperature of 0.7, performance significantly exceeds traditional greedy decoding.
This is an entirely unsupervised technique that requires no additional training, fine-tuning, or human annotation—working off-the-shelf with pre-trained language models to substantially improve reasoning performance.
Prompt Templates
How to apply Self-Consistency:
- 1Run each prompt 5–10 times with temperature≈0.7. The higher the temperature, the more creative the LLM gets. This also means that each iteration will yield a different answer.
- 2Extract the Final Answer token from every run.
- 3Return the majority answer to stakeholders; log chains for auditability.
Choosing the right LLM for Self-Consistency Prompting in 2025
Key points:
- Reasoning Power is a rough guide taken from ARC-AGI or similar public scores where available.
- Price shows current API list rates (input / output). If the model is open-source you just pay for compute.
- Good Sample Count = how many parallel “paths” usually give the best accuracy-for-cost in self-consistency: stronger models need fewer; weaker ones need more.Always run each sample at temperature ≈ 0.7 to get diverse chains, then majority-vote the answers.
- Check latency: more samples = longer wait unless you parallelize.
Use this chart to match your budget, accuracy target, and context-length needs when rolling out self-consistency prompting in production.
Empirical Performance
The graphs show better performance of the self-consistency prompting method over sample & rank (multi-path) and greedy decode (single-path) on various benchmarks | Source: Self-Consistency Improves Chain of Thought Reasoning in Language Models
Let’s see how LLMs in 2025 are performing on various reasoning benchmarks suited for the Self-consistency prompting technique.
In the table above:
- Higher % = better. The score shows how often the model got the answer right after it tried several reasoning paths and picked the most common answer.
- Big gains (like o4-mini on AIME) come from letting the model “think out loud” many times (usually 5-10 runs) and then vote.
- Tough benchmarks such as ARC-AGI and HLE still stump most models, even after voting, but top reasoning models (o-series) are pulling ahead.
If we keep the scaling law in mind, it is better to opt for larger models if you are looking for multiple reasoning paths. One reason is that these models are trained using scaled reinforcement learning (RL). This means the models can spend more time and compute to generate longer and multiple reasoning steps or long-CoT for solving difficult problems.
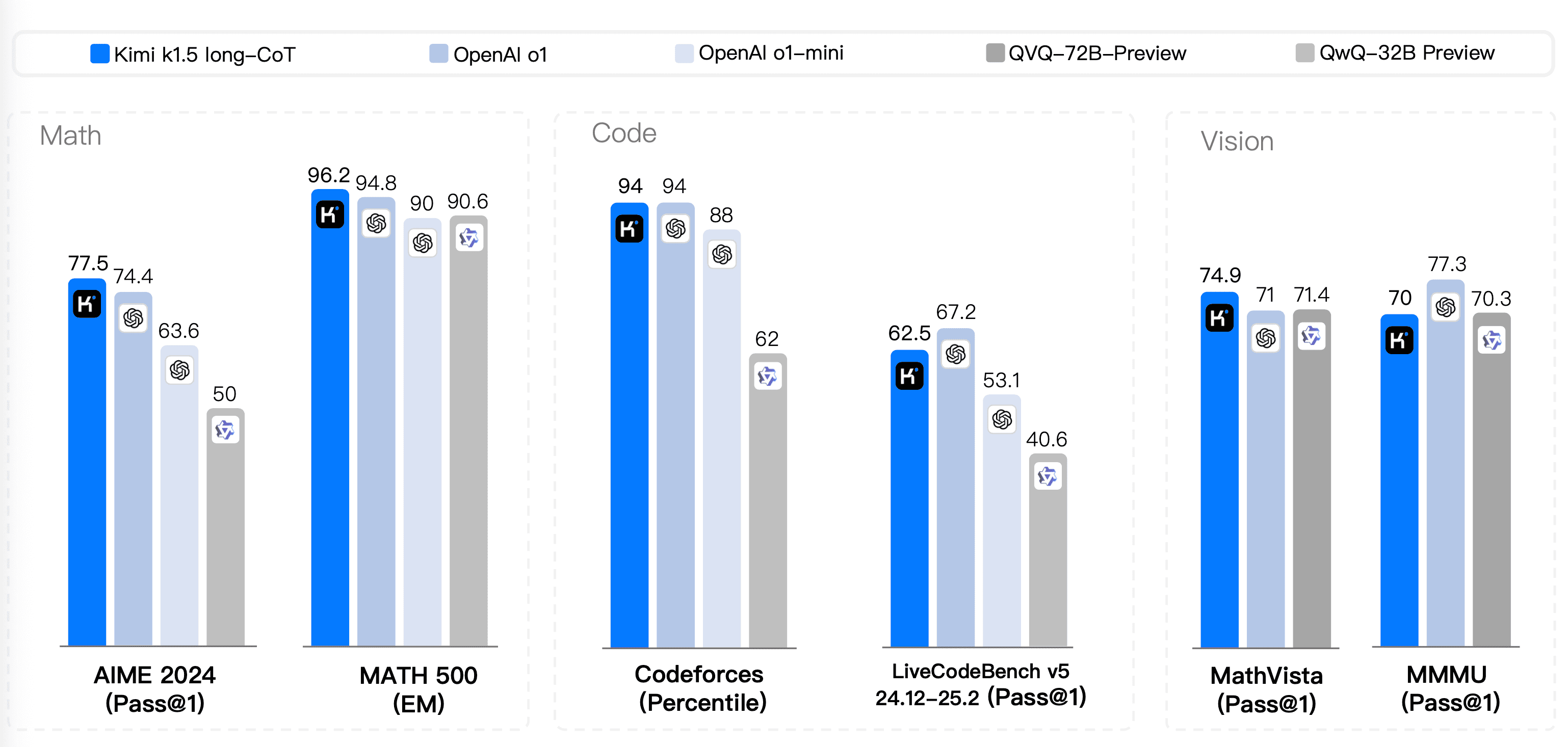
Comparison of various LLMs in different benchmarks with long-CoT | Source: Kimi k1.5: Scaling Reinforcement Learning with LLMs
Scaling RL in train-time promotes enhanced reasoning and better output generation.
Pros, Cons & Common Pitfalls
Pros
- Better answer accuracy: When the model tries many reasoning paths, it can vote on the result that appears most often. This usually leads to a higher chance of choosing the correct answer.
- Built-in error checking: If one path makes a mistake, other paths may still find the right answer. Taking a majority vote reduces the impact of single-path errors.
- No extra training required: The method works with any pre-trained model. You do not need to fine-tune or label more data.
- Simple confidence signal: A large agreement among paths suggests the answer is reliable. A split vote warns that the output may be uncertain.
- Compatible with Chain-of-Thought (CoT): Self-consistency adds an extra “safety net” on top of step-by-step reasoning, improving difficult tasks such as math or logic puzzles.
Cons
- Slower response times: Each additional path takes time. Ten paths can be roughly ten times slower than one.
- Higher token costs: You pay for every generated path. Running many paths on large models can become expensive.
- Greater computing load: Parallel generation increases CPU /GPU use and may require more powerful servers.
- Less helpful on open-ended tasks: Tasks like creative writing or summarization often do not have a single “right” answer, so majority voting adds little value.
Common Pitfalls
Using Adaline for Self-Consistency Prompt Engineering
In this section, I will show you how to use Adaline.ai to design your prompts.
First, you will need to select the model. For this example, I will choose GPT-4.5 as it is a fast model. We will also set the temperature at 0.7. But feel free to use any model that fits your needs. Adaline.ai provides a wide variety of models from OpenAI, Anthropic, Gemini, Deepseek, Llama, etc.

Second, once the model is selected, we can then define the system and user prompts.

The system prompt defines the role and purpose of the LLM for a particular task. In this case, “You are a careful reasoning assistant…”
The user prompt defines the task at hand – what it needs to do when provided with a piece of information. Using this structured approach will yield better results and greater robustness.

Third, once the prompts are ready, just hit run in the playground.

Adaline.ai will execute your prompts using the selected LLM and provide you with the answer.

Now, since we are dealing with a self-consistency prompting method, we need to check out a few more outputs from the model. This will help us to evaluate consistency with GPT4.5. To do that, just click on “Add message.”

“Add message” will allow you to add a follow-up prompt that will continue the conversation to yield more outputs.
Once you add a follow-up prompt, click on “Run.” It will continue the conversation from the previous output. Look at the example below.

Here, I have added “Provide one more solution” as a user prompt.
Likewise, you must prompt the LLM to provide additional outputs to verify consistency.
Adaline.ai provides a one-stop solution to quickly iterate on your prompts in a collaborative playground. It supports all the major providers, variables, automatic versioning, and more.
Get started with Adaline.ai.
FAQ
What Is Self-Consistency Prompting?
Self-consistency prompting is a sampling technique that runs the same chain-of-thought prompt several times at a higher temperature, then picks the answer that appears most often. The intuition: if many reasoning paths converge on the same conclusion, that conclusion is more likely to be correct.
Self-Consistency Prompting vs Chain-of-Thought: What Is the Difference?
Chain-of-thought prompts the model to reason step-by-step in a single sample. Self-consistency wraps the chain-of-thought in a majority vote across many samples. The cost rises with sample count, but accuracy gains can reach 10 to 20 percentage points on hard reasoning benchmarks.
When Does Self-Consistency Prompting Work Best?
It works on tasks with a single right answer and multiple valid reasoning paths, like arithmetic, multi-step math, code generation with test cases, and structured logic puzzles. It works poorly on open-ended writing, creative generation, or tasks where many answers are equally valid.
What is the self-consistency approach?
Ask for several “think-out-loud” paths, not just one. Collect the final answers and choose the majority as correct.
What is a self-consistent chain of thought?
Each path follows step-by-step “Chain-of-Thought” reasoning. Self-consistency then finds the most common result across those paths.
What is prompt chaining?
Prompt chaining involves splitting a large task into smaller prompts. The output of one prompt becomes the input for the next, like links in a chain.
What are meta prompts?
Meta prompts give the model rules on how to write or think, not just what to answer. They guide style, tone, or problem-solving steps.
What is tree of thought prompting?
In the tree of thought prompting, the model explores many branching ideas, like a tree with several paths. It then scores or prunes branches to keep only the best reasoning.