
The foundational research on LLM-as-a-judge found that GPT-4 agrees with human evaluators more than 80% of the time. This is the same rate at which humans agree with each other.
Lianmin Zheng and colleagues at UC Berkeley published that finding in 2023, and it made automated LLM evaluation mainstream almost overnight. If a language model could approximate human judgment at human-level consistency, the case for replacing annotation pipelines with API calls would be settled.
The research that followed has been less reassuring. Studies published in 2025 and early 2026 have systematically documented where LLM judges fail, why they fail, and how often. No judge evaluated by the RAND Corporation's research team was uniformly reliable across benchmarks. Frontier models exceeded 50% error rates on advanced bias tests, according to Hongli Zhou and colleagues' JudgeBiasBench. Simple text formatting changes disrupted consistency among judges who passed standard accuracy checks.
LLM-as-a-judge works. The 80% finding is real. But it comes with conditions most production evaluation pipelines do not fully preserve, and the research is now specific enough to act on.
Why Did LLM-as-a-Judge Become the Default for LLM Evaluation?
Three Failure Modes That Have Since Been Documented
The field has converged on a taxonomy of failure. Bo Yang and colleagues, who published FairJudge in February 2026, identified three compounding limitations that explain why LLM-as-a-judge breaks down in production.
- 1
Adaptivity failure
Here, a judge prompted for general chat quality applies the same rubric to code review, medical summarization, and creative writing. The evaluation criteria that predict human preference in conversation do not transfer cleanly to domain-specific tasks. This leads a judge to score a RAG pipeline response using chat-quality heuristics, measuring something other than what the task actually requires. - 2
Non-semantic bias
The bias does not come from what the judge reads; it comes from how the response looks. Position, length, formatting, and model provenance all shape the verdict in ways unrelated to actual content quality. This means two responses of equal substance can receive different scores based on which appeared first in the prompt. - 3
Cross-mode inconsistency
Mixing pointwise and pairwise evaluation introduces a structural problem, i.e., the judge contradicts itself. A response rated 8 out of 10 in pointwise scoring can still lose a direct pairwise comparison with a response rated 7 out of 10. FairJudge calls this Score-Comparison Inconsistency, and it leads to circular preference chains where A beats B, B beats C, and C beats A.
These three failures compound in practice. And they do not simply add up, because each failure mode makes the others harder to detect. A judge using the wrong rubric will also register non-semantic cues, then produce pointwise scores that contradict its own pairwise judgments. Building a reliable LLM evaluation framework means addressing all three, not just the most visible one.
The second failure mode, non-semantic bias, is where the most specific and actionable research has been published.
The Specific Bias Types and What Triggers Them
The standard LLM evaluation metrics — average agreement rate, benchmark accuracy — do not surface these bias types. Four distinct types are now documented with sufficient empirical grounding to act on.
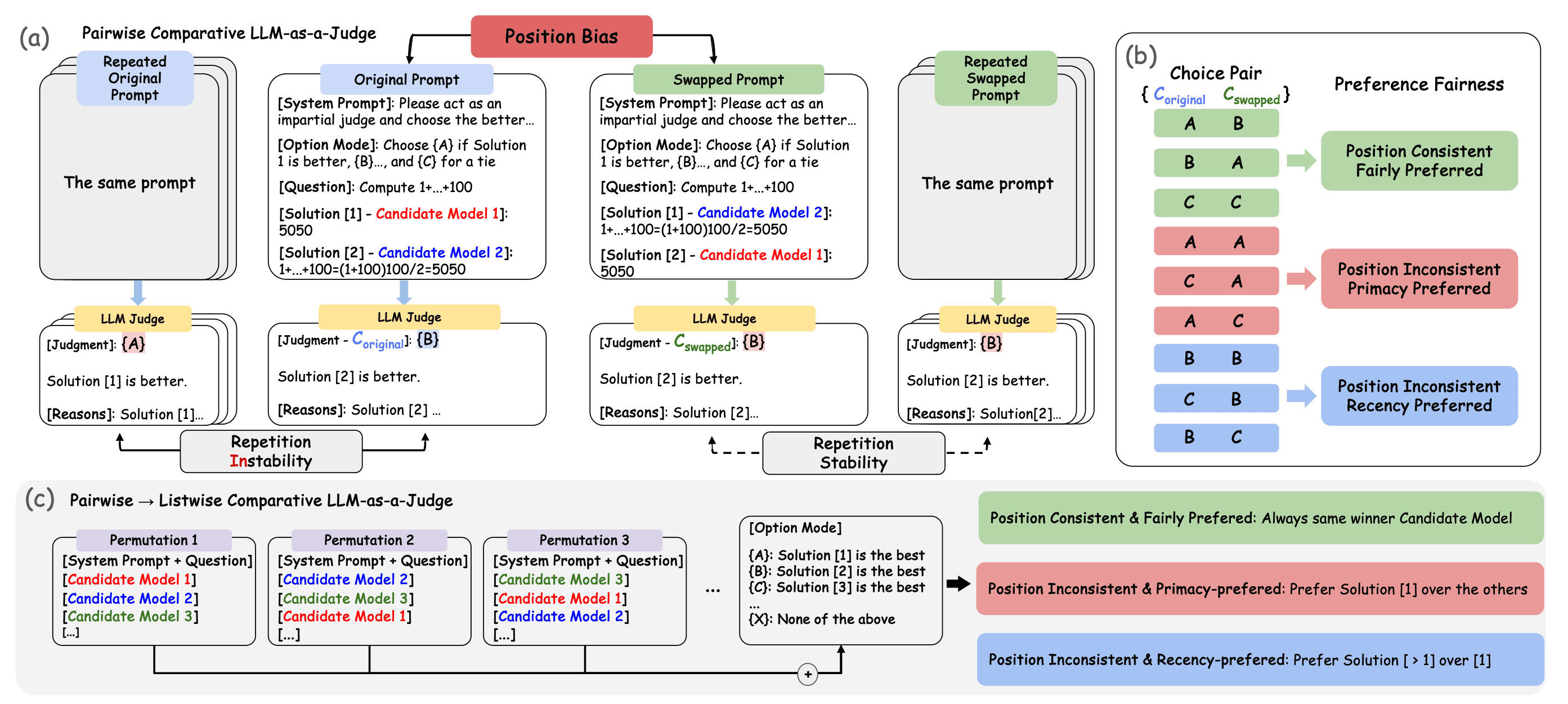
Position bias in pairwise LLM-as-a-judge evaluation. When candidate positions are swapped, judges can flip their verdict (repetition instability) or hold it (repetition stability). The choice pair framework classifies outcomes into position-consistent, primacy-preferred, and recency-preferred — the three behavioral signatures of position bias. From Lin Shi and colleagues (IJCNLP 2025). | Source: Judging the Judges: A Systematic Study of Position Bias in LLM-as-a-Judge
Lin Shi and colleagues studied position bias across 15 judges and approximately 150,000 evaluation instances at IJCNLP 2025. They found that the bias varies significantly across judges and tasks and is not due to random chance.
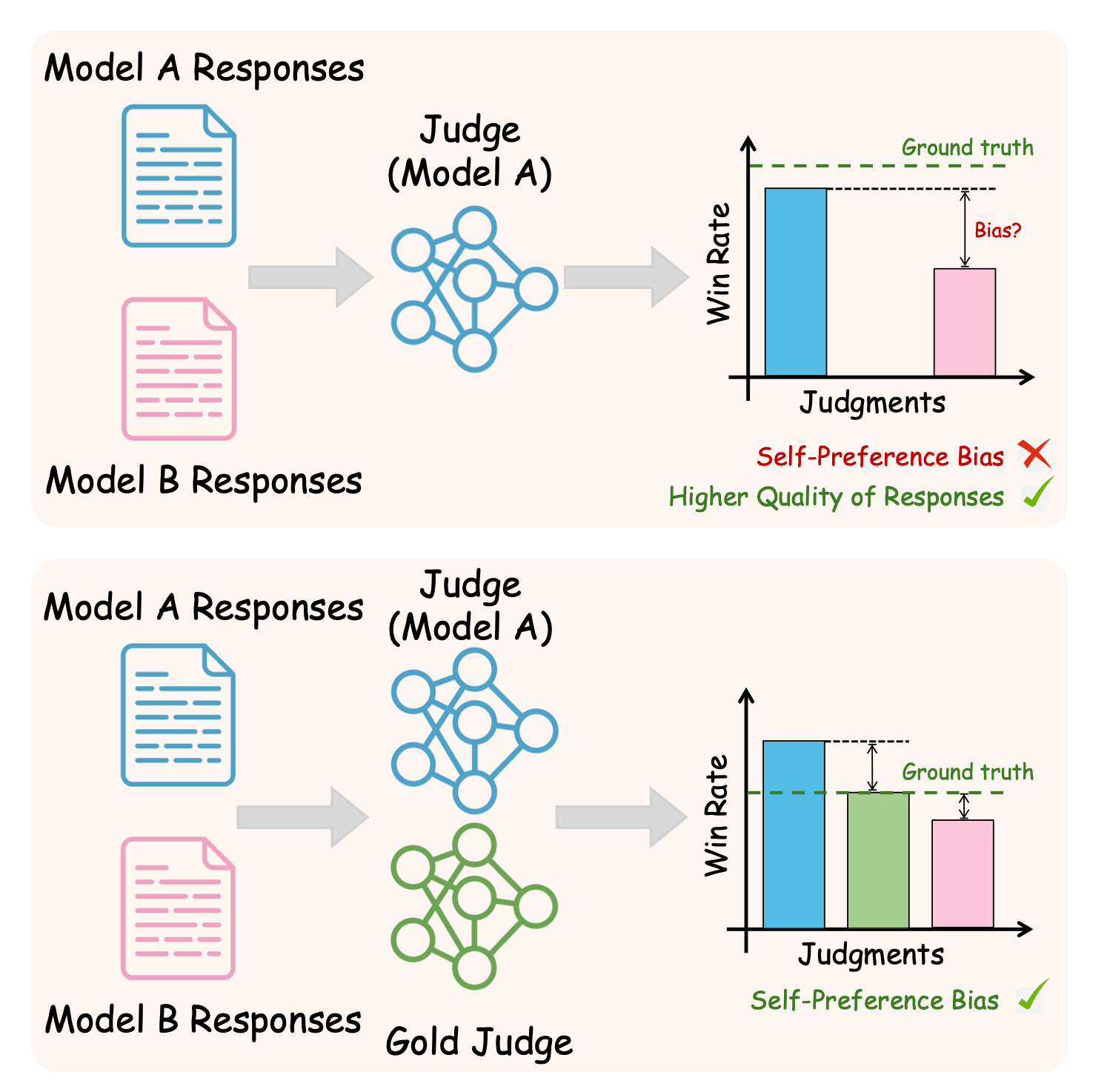
Self-preference bias in LLM-as-a-judge. Top: a judge evaluating its own model's outputs inflates win rates above ground truth — but the gap is ambiguous without a reference. Bottom: adding a gold judge from a separate model family surfaces the bias by showing where the two judges diverge. | Source: Beyond the Surface: Measuring Self-Preference in LLM Judgments
Research published at EMNLP 2025 documented self-preference and family bias and drew a distinction that matters in practice. Not every preference a model shows for its own outputs is biased; some of it reflects genuine quality differences. The harmful part is when a model fails to penalize its own errors.
The common thread: in each case, the judge is responding to something other than the content being evaluated.
How Reliable Is LLM-as-a-Judge? What the 2026 Research Found
The 80% aggregate agreement figure is accurate, as Lianmin Zheng and colleagues measured across 3,000 expert votes in the original MT-Bench study. It is also a misleading starting point for production decisions. Because it describes average performance across benchmarks, the failure cases are not distributed evenly.
If you are running an evaluation on production outputs, the aggregate accuracy figure is not the right measure to watch. What matters is how your judge performs on the borderline outputs your model actually generates.
Morgan Sandler and colleagues at the RAND Corporation released the Judge Reliability Harness in March 2026. It is an open-source library that stress-tests LLM judges across consistency and discriminative tests. After evaluating four judges across safety, persuasion, misuse, and agentic benchmarks, they concluded that no judge was uniformly reliable. Consistency broke down on inputs as simple as formatting changes, paraphrasing, and shifts in verbosity.
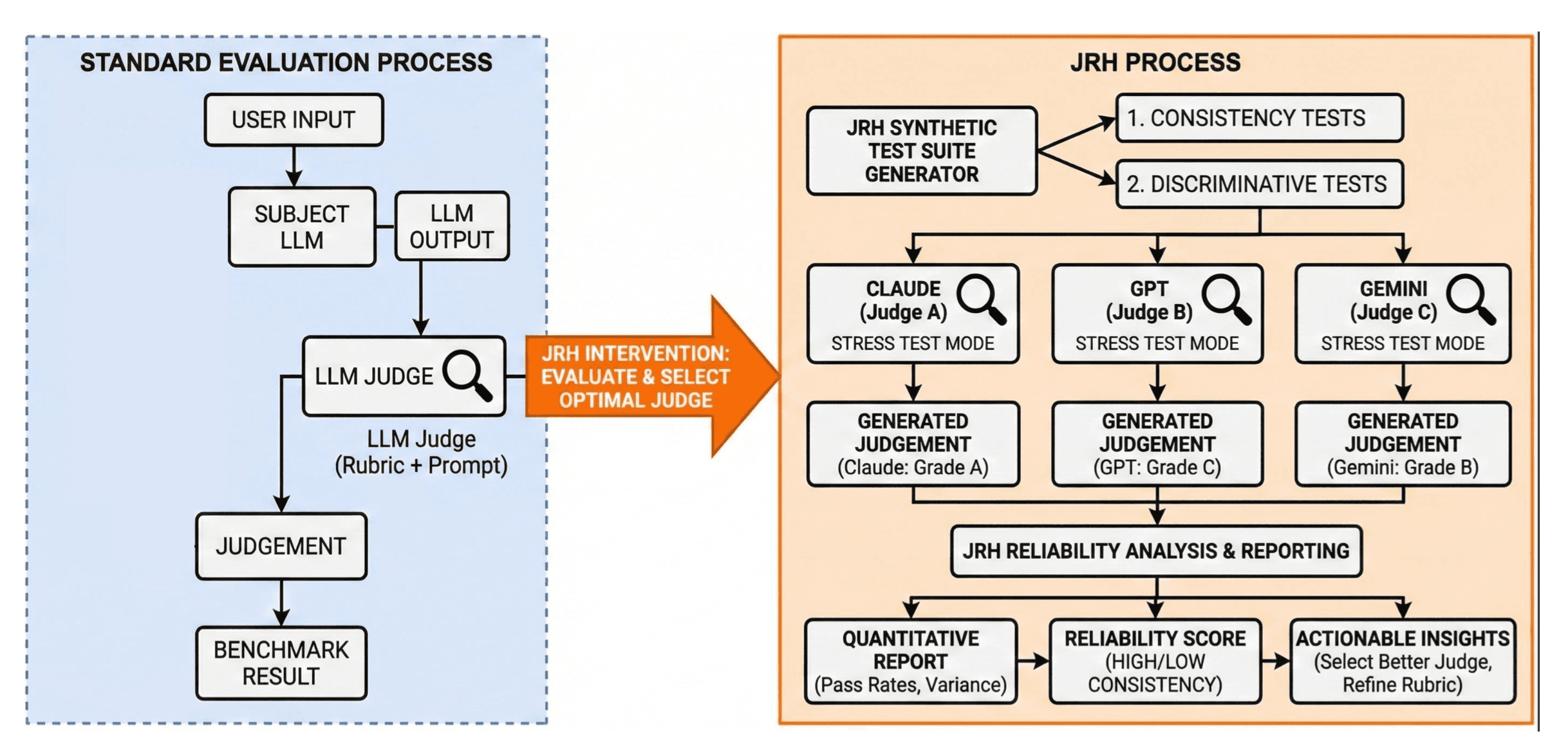
The Judge Reliability Harness (JRH) process from Morgan Sandler and colleagues at the RAND Corporation (2026). Where standard evaluation uses a single judge and produces a benchmark result, JRH stress-tests multiple judges with synthetic consistency and discriminative tests, then scores each judge's reliability and surfaces which to use. | Source: Judge Reliability Harness: Stress Testing the Reliability of LLM Judges
Hongli Zhou and colleagues published JudgeBiasBench the same month, documenting 12 bias types across four dimensions. Their central finding: even frontier LLMs exceeded 50% error rates on challenging bias benchmarks.
The implication for production is direct: edge cases are where judge reliability matters most, and edge cases are where it most often fails. This is especially relevant for teams evaluating AI agents, where the judge must assess multi-step behavior rather than a single response.
How to Build LLM Evaluation Pipelines That Account for These Failures
None of this means abandoning LLM-as-a-judge. It means building around its documented failure modes. There are four interventions with research backing.
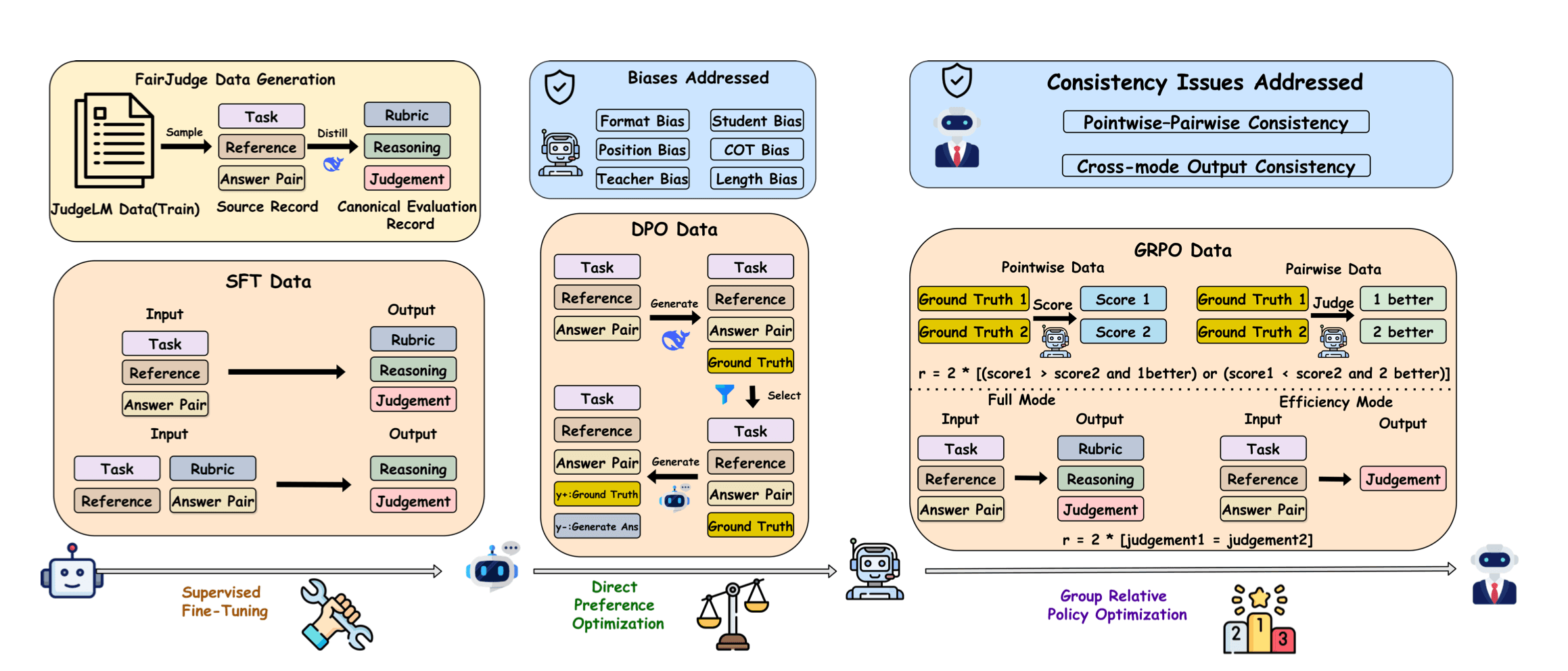
FairJudge's three-stage training pipeline, from the Bo Yang et al. (2026) paper. SFT establishes the base judge behavior; DPO targets non-semantic biases, including position, format, and length; GRPO enforces consistency across scoring modes. | Source: FairJudge: An Adaptive, Debiased, and Consistent LLM-as-a-Judge
- 1
Calibrate your judge to your domain
An off-the-shelf judge validated on chat conversations is not reliable for RAG evaluation, code review, or agent task assessment without domain-specific calibration. Compare its verdicts against human spot checks on representative inputs before deploying to production. Divergence rates above 20–25% signal the need to recalibrate the rubric. - 2
Use reference-guided grading where possible
This technique, identified in the original MT-Bench paper, reduces the influence of prior biases by anchoring evaluation to a fixed standard. When a correct reference exists, it is consistently more reliable than prompt-only scoring. - 3
Use meta-judge approaches over debate-style ensembles
Research published at EMNLP 2025 found that multi-agent debate frameworks amplify bias after the first round. Meta-judge approaches, in which one LLM evaluates the judgments of other LLMs rather than their original outputs, showed greater resistance to those biases. - 4
Separate your judge's model family from your generator's
Family bias means that using Claude to judge Claude outputs compounds self-preference in ways individual-model bias data does not capture. A judge from a different provider systematically reduces this.
Running the same evaluation set across multiple judge models and comparing agreement rates surfaces bias profiles, with no labeled ground truth needed. Adaline's evaluation workflow makes this trackable across model versions and task types. Teams building from first principles can start with the LLM evaluation fundamentals before adding judge-specific configuration.
Frequently Asked Questions
What is LLM-as-a-judge?
LLM-as-a-Judge is an evaluation pattern where one large language model scores or compares outputs from another LLM. It substitutes for human review on tasks like answer quality, factuality, and instruction following, trading some judgment fidelity for scale and speed.
How reliable is LLM-as-a-judge?
Strong LLM judges achieve over 80% agreement with human evaluators on well-structured tasks. However, a 2026 RAND Corporation study found that no judge is uniformly reliable across benchmarks. And frontier models exceeded 50% error rates on challenging bias benchmarks. Reliability depends on the judge model, task type, and evaluation structure.
What is position bias in LLM-as-a-judge?
Position bias is when an LLM judge favors a response based on where it appears in the prompt rather than its quality. Research across 15 judges and approximately 150,000 evaluation instances found that this bias is not random. It varies significantly across judges and tasks and is strongly affected by the degree of similarity in response quality.
What are the main biases in LLM evaluation?
The main biases documented in LLM-as-a-judge research are: position bias (favoring responses by presentation order), verbosity bias (favoring longer responses as a proxy for quality), self-preference bias (models scoring their own outputs higher), and family bias (models scoring the same-provider outputs higher). Each has specific trigger conditions and targeted mitigations.
How do you reduce bias in LLM-as-a-judge?
Four mitigations have research backing: calibrate your judge against human spot-checks for your specific domain; use reference-guided grading where a correct reference answer is available; use meta-judge approaches rather than debate-style multi-model setups, which amplify bias; and use a judge model from a different provider than your generator model.
LLM-as-a-Judge vs Human Evaluation: Which Should You Use?
Use human evaluation as the gold standard for any production launch decision. Use LLM judges for regression testing, large-scale pre-screens, and high-frequency monitoring where human review cannot keep up. Pair the two: human-label a small set, audit judge agreement against it.
Conclusion
The 80% agreement finding and the 50% error rate on bias benchmarks are not in conflict. They describe the same system operating under different conditions. The first was measured on strong judges, well-structured tasks, and controlled settings. The second was measured by the kinds of perturbations that production inputs routinely introduce.
The teams that build reliable evaluation pipelines are not the ones who accept either finding as the complete picture. They are the ones who understand the conditions under which each result holds and design their pipelines to preserve those conditions for the first result while systematically testing for the second.
Evaluation is itself a system that requires evaluation. A judge that performs well on your benchmark but breaks on text formatting changes is not a reliable judge for your production use case. The research now exists to know the difference. The question is whether you have built the pipeline to surface it.