
There is a specific moment every team shipping an LLM-powered feature hits: a user finds something the team didn't. For instance, the model returned a confident, well-formatted response, and it was completely wrong. The team cannot reproduce it, cannot explain it, and cannot say whether it is happening to 1% of users or 40%.
That is not a model problem. It generally falls under the evaluation problem.
Let's understand this thoroughly.
Every team shipping reliable AI products runs a structured LLM evaluation program. This guide covers how to evaluate large language models at every stage, i.e., from single LLM calls to multi-step agent pipelines. Not because they have more time, but because without it, they are shipping blind. LLM evaluation is how you close the gap between a system that works in a controlled test and one that works at scale, across the full range of real user inputs, consistently over time.
This article maps the full evaluation landscape:
- 1The three evaluation methods and when to use each.
- 2The metrics that match specific task types.
- 3Why standard benchmarks don’t predict production performance.
- 4How to build a framework that runs continuously?
- 5What changes when your system is an agent rather than a single LLM call?
What Is LLM Evaluation and Why Does It Matter?
LLM evaluation is the practice of measuring an AI system's performance against defined success criteria using structured, repeatable tests. It involves three components: a test dataset, a success criterion, and an evaluator. Unlike traditional software testing, LLM evaluation accounts for nondeterminism. The same input can produce different outputs across runs.
The word nondeterminism is doing important work in that definition. Traditional software is deterministic: given the same input, it produces the same output. You write a test, it passes or fails, you ship. LLMs don't work that way. The same prompt can produce outputs that differ in structure, length, tone, and accuracy across calls.
That variability is not a bug. It is how language models work. And it means that testing a system once and moving on is not testing at all.
This is why LLM evaluation has three distinct components.
- 1The test dataset is a curated collection of representative inputs — typical cases, edge cases, and adversarial inputs.
- 2The success criterion is an explicit definition of what correct output looks like for each case.
- 3The evaluator is the mechanism that scores outputs against those criteria — and it can be a script, a human reviewer, or another AI model.
OpenAI’s evaluation documentation makes this operational: run evals on every change, not just at launch. This practice, eval-driven development, treats evaluation as infrastructure rather than a final quality check. For the foundational principles behind how this works in practice, LLM evaluation fundamentals covers the concepts in full. For the specific signals and metrics that matter most at the product decision level, evaluation metrics product leaders maps the criteria clearly.
With the definition in place, the next question is which evaluation method fits which problem, because metric-based, human, and LLM-as-a-judge evaluations each solve a different root cause of failure.
LLM Evaluation Methods: When to Use Each
Not all evaluation methods are equal. And they are not interchangeable. Metric-based evaluation, human evaluation, and LLM-as-a-judge each solve a different problem. Choosing the wrong one at the wrong stage is one of the most common reasons evaluation programs fail to improve production quality.
Here is how they compare:
Metric-based evaluation uses programmatic checks — ROUGE scores, exact match, F1 — that run instantly at scale. They are the right tool for regression testing: verifying that a prompt change didn't break something that was working. Their limitation is precision. They measure surface patterns, not whether the output is actually useful or correct.
Human evaluation produces the highest-quality signal and is the baseline that every other method calibrates against. It is slow and expensive at scale. Its role in a mature eval program is to set the quality standard, not to run on every change.
The Autorubric evaluation architecture: a RubricDataset (prompt + rubric + items) feeds an EvalRunner, which calls Rubric.grade() per data item. The CriterionGrader runs N judges × M criteria as N·M parallel calls via asyncio.gather() — with options shuffled to counteract position bias. Votes aggregate via majority or weighted scoring into a final Ensemble Evaluation Report. A single LLM is treated as an ensemble of one. | Source: Rao & Callison-Burch, Autorubric (ArXiv 2603.00077, February 2026).
LLM-as-a-judge uses a capable model to score outputs against defined criteria. OpenAI's evaluation documentation confirms that strong LLM judges achieve agreement rates of over 80% with human annotators. This matches the agreement rate observed among human annotators. Delip Rao and Chris Callison-Burch's February 2026 Autorubric paper documents the two main failure modes:
- 1
Position bias
The judge favors whichever response appears first. - 2
Verbosity bias
The judge favors longer responses regardless of quality.
Careful prompt design and multi-judge ensemble aggregation address both. For the full mechanism behind LLM-as-judge evaluation, that article covers how to implement it reliably. For the techniques that go beyond these defaults, advanced eval methods cover the full range.
The decision rule across all three: start with metric-based for speed, calibrate with human evaluation for accuracy, then scale with LLM-as-a-judge once your rubric is validated against human scores.
Understanding which method to use is half the decision. The other half is knowing what to measure and the right metrics depend entirely on the task.
LLM Evaluation Metrics: What to Measure and When
The metric you choose must match the failure mode you are trying to catch. Using ROUGE to evaluate a conversational AI assistant is like using a stopwatch to measure temperature. It produces a number, but not a useful one.
ROUGE and BLEU measure n-gram overlap between the model's output and a reference answer. For BLEU and ROUGE metrics, the core limitation is shared: they reward surface similarity, not semantic accuracy. A paraphrase that is equally correct will score poorly against a reference that uses different words.
BERTScore addresses this by computing similarity in embedding space. Essentially, capturing meaning rather than exact wording. It is better suited for tasks where correct answers can be expressed in multiple ways.
For RAG systems, context precision and context recall are the right metrics. OpenAI's evaluation documentation sets concrete targets: context recall of at least 0.85 and context precision above 0.7 as baseline success criteria for document Q&A tasks.
Context recall, in particular, measures how much of the relevant ground truth the retrieval surface — a missing fact in the retrieved context is a ground truth miss before the model even sees it. Faithfulness measures whether the model's output is grounded in what was actually retrieved — it is the primary metric for catching hallucinations in retrieval-augmented systems. For the full framework behind RAG evaluation, including how to apply these metrics in production pipelines, that article covers the implementation in depth.
The principle that unifies all of them: define which metric you will use before you write the prompt, not after. A metric chosen after the fact is chosen to justify a decision already made, not to measure whether it was correct.
These metrics apply to single LLM calls. But before building your own eval set, a natural question surfaces — can't you just use standard benchmarks to compare models?
What Standard Benchmarks Actually Tell You (and What They Don't)
Benchmarks like MMLU and HumanEval are designed to compare model capabilities across standardized tasks. They are useful for understanding a model's overall reasoning level. They are not useful for predicting how that model will perform on your specific task, with your data, at your quality bar.
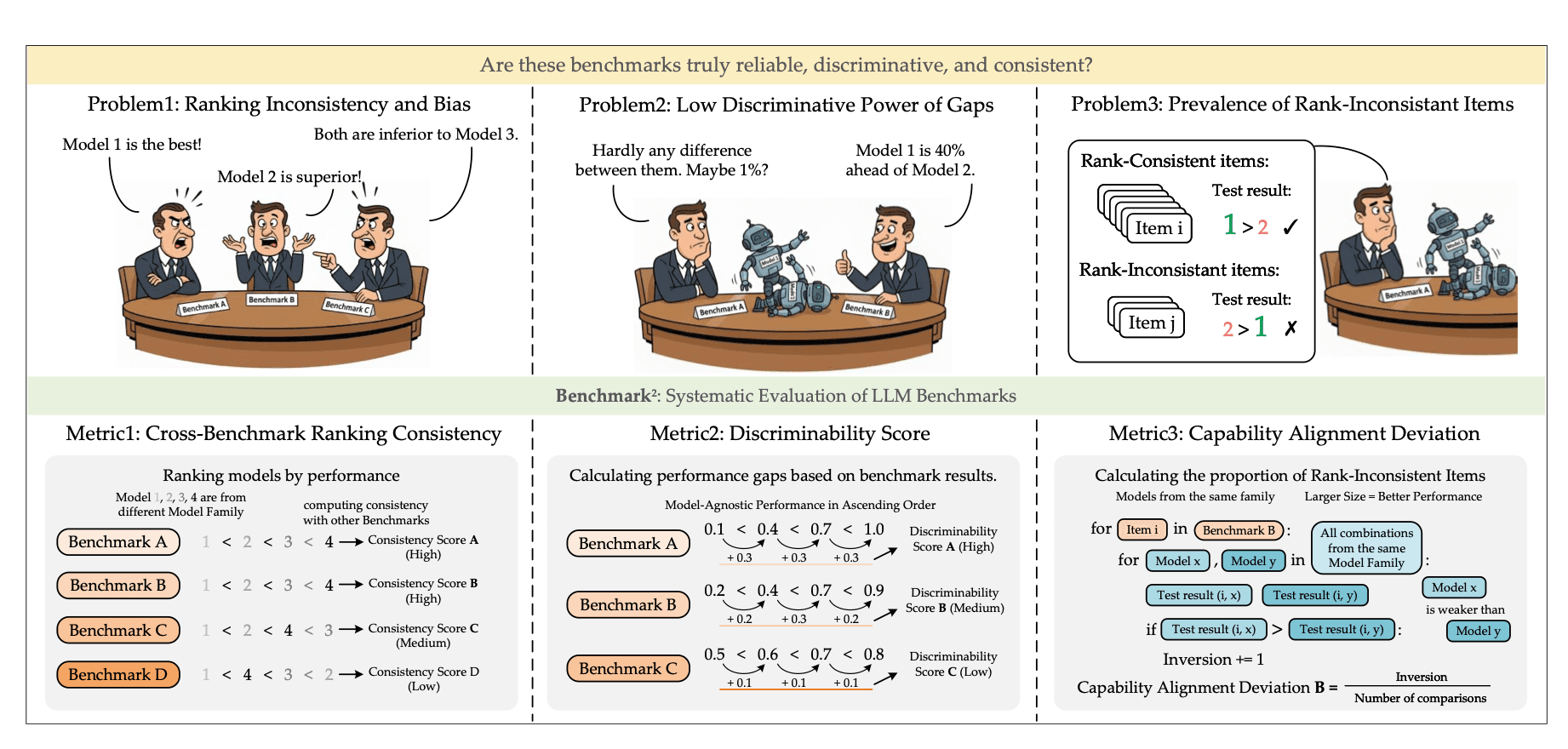
The Benchmark² framework from Qi Qian and colleagues at Fudan University identifies three structural problems with standard LLM benchmarks: ranking inconsistency across benchmark sets (Problem 1), low discriminative power between models (Problem 2), and prevalence of rank-inconsistent test items (Problem 3). To address these, the paper introduces three benchmark quality metrics — Cross-Benchmark Ranking Consistency, Discriminability Score, and Capability Alignment Deviation — each measuring a distinct axis of benchmark reliability. | Source: Qian et al., Benchmark² (ArXiv 2601.03986, January 2026).
The gap is not subtle. Qi Qian and colleagues at Fudan University confirmed this formally in their January 2026 paper, Benchmark². Evaluating 11 LLMs across 15 benchmarks spanning mathematics, reasoning, and knowledge tasks, they found significant quality variations in the benchmarks themselves, independent of the models being tested. They introduced three metrics for evaluating benchmark quality:
- 1
Cross-Benchmark Ranking Consistency
Do the model rankings produced by this benchmark agree with those of peer benchmarks? - 2
Discriminability Score
Can this benchmark tell models apart, or do strong and weak models cluster together? - 3
Capability Alignment Deviation
Does a stronger model within the same family consistently outperform a weaker one, or do the results invert?
Many widely used benchmarks score poorly on all three. The practical implication is this: use LLM benchmarks to shortlist models based on general capability. Then, validate on your own task-specific eval set built from real inputs. Evaluation benchmarks that actually drive product decisions require your inputs, your success criteria, and your definition of correct — not a shared leaderboard that optimizes for average performance across hundreds of unrelated tasks.
With the right metrics and a realistic picture of what benchmarks can and can't do, the next step is to assemble those pieces into a continuously running framework.
How to Build an LLM Evaluation Framework
An LLM evaluation framework is the infrastructure that makes evaluation repeatable, scalable, and continuous — not a one-time quality gate. For the PM guide to LLM output evaluation, the core principle is the same as it is for engineers: define success before you measure it. An evaluation framework has four components, and the order in which you build them matters. The four components below form a complete LLM evaluation framework you can run in production.
- 1
Define success criteria first.
Before writing a prompt or collecting test data, write the definition of what a correct output looks like. Not "it should sound helpful," but "it should extract these three fields, in this format, from this class of input, and handle this edge case this way." A vague success criterion produces a useless eval because any output can be defended as good enough. - 2
Build the test dataset.
A useful eval set contains three types of inputs: typical cases that represent the real distribution of user behavior, edge cases at the boundary of the system's intended scope, and adversarial cases designed to surface failure modes before users do. OpenAI recommends mining production logs for test cases — the actual inputs your users send are more informative than synthetic ones. - 3
Choose and calibrate your evaluator.
Start with metric-based evals for speed and repeatability. Calibrate with human evaluation to set the quality bar and validate that your metric captures what you actually care about. Scale with LLM-as-a-judge once the rubric has been validated against human scores. For technical approaches to LLM evaluation, the implementation details at each layer matter as much as the selection of the method. For prompt-specific workflows, a prompt evaluator runs structured scoring against your rubric on every prompt variant — this is where tools like Adaline's evaluation module fit into the framework. - 4
Integrate into CI/CD.
Run evals on every prompt change, not just at launch. This is what transforms evaluation from a one-time quality check into a continuous reliability signal. Implementing eval systems at production scale requires automation at this step — and the technical eval implementation underneath that automation determines whether the system is maintainable over time.
For the end-to-end evaluation framework design — including how to structure the test dataset, write rubrics, and handle multi-step workflows — that article covers the full architecture.
Production evaluation is what separates a framework from a launch checklist. This framework applies to single LLM calls and chained workflows alike. When the system is an agent, making decisions across multiple steps, the architecture has to change.
LLM Agent Evaluation: What Changes in Multi-Step Systems
LLM agent evaluation requires a different infrastructure than single-call evaluation because errors compound across steps.
A single LLM call has one input, one output, and one success criterion. Evaluation is straightforward. An agent makes decisions across multiple steps, calls tools, and builds toward a goal over an extended interaction. The failure modes are fundamentally different.
The core problem is error propagation. In a multi-turn agent, a mistake in step two does not stay in step two. It shapes what the agent does in step three, which shapes step four, and so on. A step-level eval that passes for every individual step tells you nothing about whether the full trajectory reaches the correct end state.
Evaluating AI agents as a discipline requires a different infrastructure than evaluating a single LLM call. Anthropic's engineering team documents this separation in their guide on agent evals. They identify three distinct infrastructure components:
- Eval suite: The collection of tasks that measure specific agent capabilities, such as customer support resolution, multi-step research tasks, or tool-use chains under constraint.
- Agent harness: The system that enables the model to act as an agent, executing tool calls and managing orchestration state across turns.
- Evaluation harness: The infrastructure that runs end-to-end tests concurrently, aggregates results across runs, and surfaces failure patterns at the trajectory level.
What to evaluate at each layer of an agent system:
- Step level: Is the agent using the correct tool with the correct arguments on each turn?
- Trajectory level: Does the sequence of decisions follow a reasonable path toward the goal?
- End-state level: Does the final output satisfy the original success criterion?
Evaluating agents in production requires all three layers to be instrumented. Evaluating only the final output misses the compounding errors that accumulate in the middle. Evaluating only individual steps misses whether those steps add up to anything useful.
Whether you are evaluating a single LLM call or a ten-step agent pipeline, the underlying principle is the same. And it only holds if evaluation is built into how you develop, not added after the fact. For teams building agentic workflows in production, Adaline's evaluation suite covers all three layers — step, trajectory, and end-state — from a single platform.
Conclusion
The discipline above — methods, metrics, benchmark limitations, frameworks, and agent-specific architecture — is not a theoretical model. It is the operational difference between teams that ship AI products that hold up in production and teams that discover their failures through user complaints.
Eval-driven development is what separates those two groups. Not more capable models, not larger context windows, not faster inference. The teams building reliable products define success before they build. They write the success criterion before they write the first prompt. They run evals on every change. They treat the evaluation system as an infrastructure that compounds in value over time, and not a checklist they run before launch.
The single habit that makes the rest of the framework work: before writing the instruction, write the definition of correct. Not "it should sound helpful." A measurable, specific, testable definition of what correct output looks like for a specific class of input, with explicit edge case handling. For the eval tooling that supports this practice in production, the infrastructure choice matters as much as the methodology.
The model is not the bottleneck. The evaluation system is. Build accordingly. For those earlier in their AI journey, the complete path to becoming an AI engineer provides the foundational context that makes evaluation work meaningful.