
Evaluating LLM reasoning capabilities has become critical for product teams building AI solutions. As models like Claude 3.7 Sonnet, Grok-3, o3, o4, and Llama 4 herd advance, understanding which benchmarks truly measure cognitive abilities—rather than just pattern matching—determines product success. These evaluations reveal how well models handle complex tasks requiring logical inference, visual understanding, and mathematical reasoning.
The landscape of reasoning benchmarks has evolved significantly, with frameworks like ARC-AGI testing abstract thinking, MMMU evaluating expert-level multimodal understanding, and specialized tests for visual and document comprehension. Each benchmark targets different cognitive dimensions, from causal reasoning to multimodal integration across images and text.
For product teams, these evaluations provide crucial insights for model selection, fine-tuning requirements, and feature prioritization. They help identify capability gaps, predict performance in real-world scenarios, and determine where custom solutions may be necessary.
Key Benchmark Categories:
- 1Core reasoning frameworks: ARC-AGI, MMLU-Pro, GPQA Diamond
- 2Visual reasoning assessments: MathVista, ChartQA
- 3Document understanding: DocVQA, TextVQA
- 4Multimodal frameworks: MMMU, Multi-Image Reasoning
- 5Performance analysis across leading models
These benchmarks collectively form the foundation for effective LLM evaluation strategies in today's rapidly evolving AI landscape.
Key reasoning benchmarks shaping LLM evaluation in 2025
Reasoning-based LLM evaluations have become essential for understanding how advanced language models handle complex cognitive tasks. These benchmarks offer product teams critical insights into model capabilities across various reasoning dimensions.
Core reasoning frameworks driving model assessment
The ARC-AGI (Abstraction and Reasoning Corpus) tests causal and abstract reasoning abilities, requiring models to solve grade-school science problems through logical inference. MMLU-Pro has emerged as a more challenging version of the original MMLU, setting higher standards for multitask understanding across domains.
GPQA Diamond represents exceptionally difficult problems that push the boundaries of current AI capabilities. Models like Gemini 2.5 Pro, DeepSeek-V3, and OpenAI ‘o’ series models currently compete for top positions on these leaderboards.
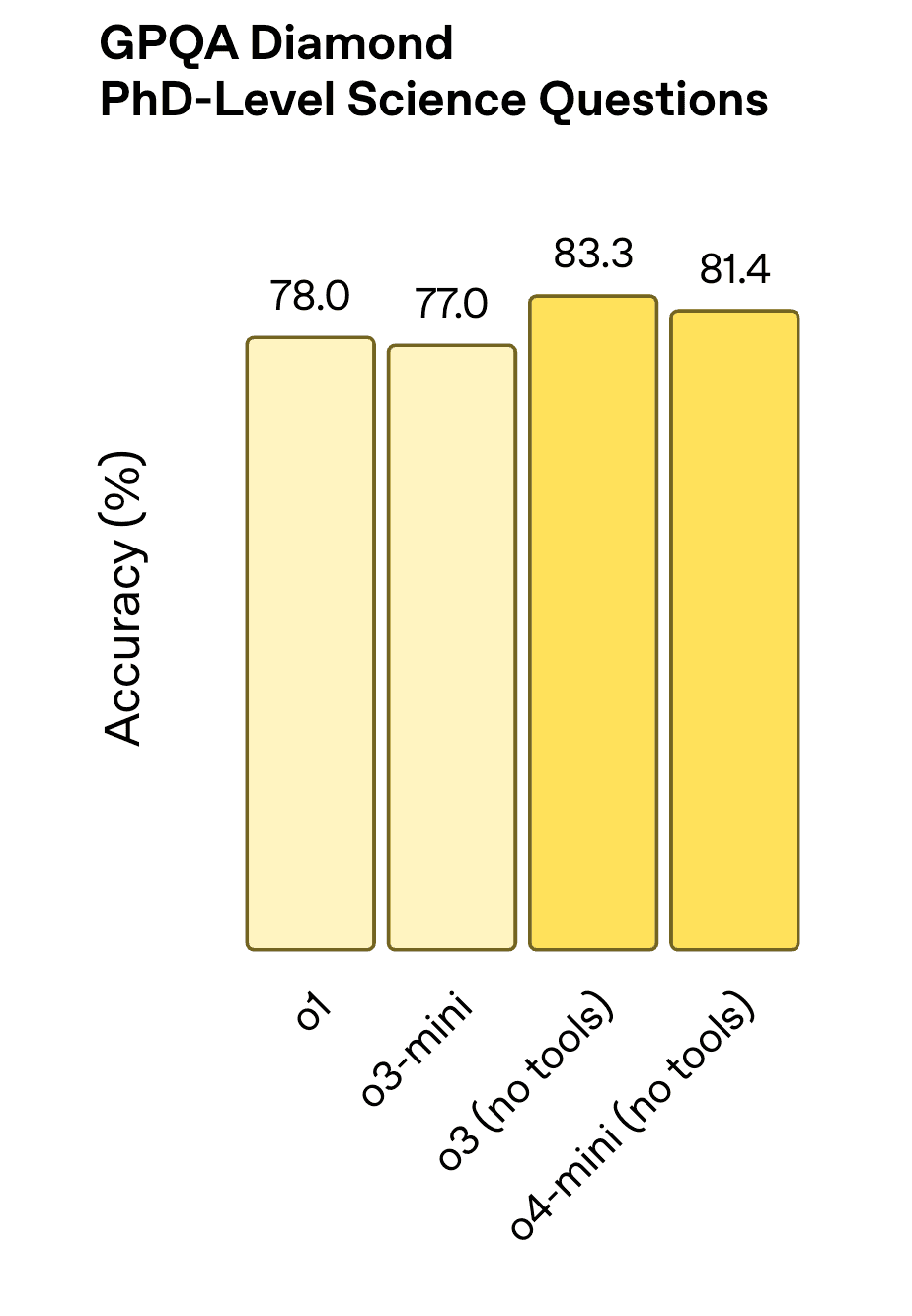
Performance improvement of OpenAI ‘o’ series model in a matter of months in GPQA dataset. | Source: Introducing o3 and o4-mini
Recent frameworks also include multimodal reasoning tests that combine text with visual elements:
- MMMU (assessing multi-domain knowledge across visual and textual understanding)
- MathVista (focusing on mathematical reasoning with visual elements)
- Multi-Image Frameworks (testing reasoning across multiple images)

Comparison of different multimodal LLMs on various LLM evals | Source: Gemini 2.5
These core frameworks establish the fundamental baseline for evaluating model reasoning capabilities across a variety of contexts.
Visual reasoning assessment evolution
Image understanding benchmarks have evolved significantly through 2024-2025. ChartQA tests models on interpreting charts and graphs, requiring both visual perception and numerical reasoning. DocVQA evaluates document understanding by measuring how well models extract information from complex documents.
TextVQA measures text recognition and comprehension in images. These benchmarks now incorporate diverse metrics including accuracy, reasoning quality, hallucination rates, and consistency.
Evolution of Visual Metrics:
The evolution of these visual benchmarks represents a significant advancement in our ability to assess how models interpret and reason with visual information.
Mathematical reasoning advancements
Significant improvements in mathematical reasoning emerged in early 2025, demonstrated in AIME 2025 performance. Leading models now show enhanced step-by-step problem solving abilities and can handle increasingly abstract concepts.
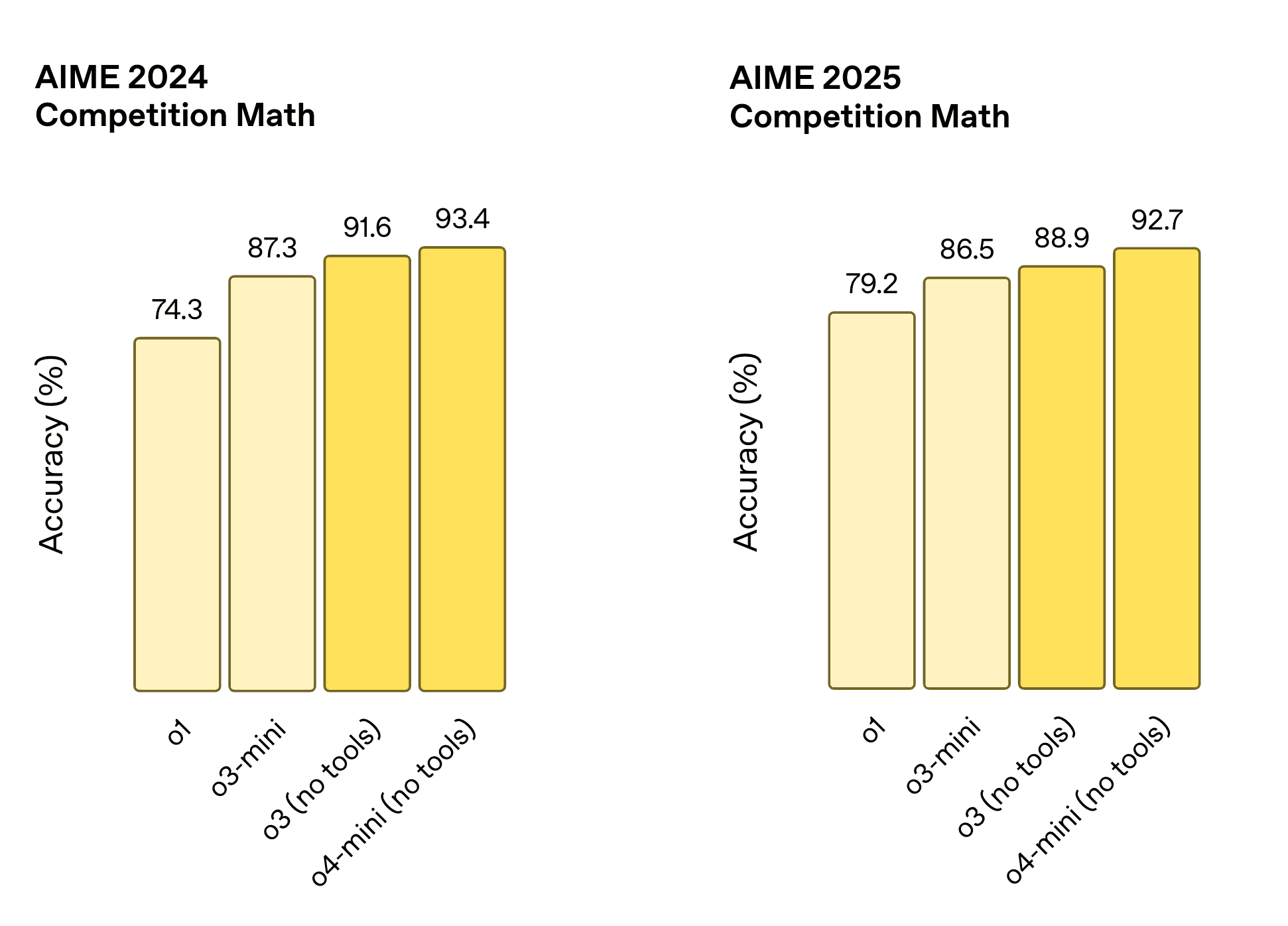
Performance improvement of OpenAI ‘o’ series model in AIME dataset. | Source: Introducing o3 and o4-mini
Chain-of-thought prompting has become standard for eliciting better reasoning, with models like Claude 3.7 Sonnet, Gemini 2.5 Pro, Grok 3, o3, and o4 demonstrating improved performance on complex reasoning tasks.
These advancements in mathematical reasoning capabilities mark a crucial step forward in the development of more capable and versatile AI systems.
Benchmark selection considerations
Product teams must carefully consider which reasoning benchmarks align with their specific use cases. Factors to evaluate include:
- 1Domain relevance (selecting benchmarks that match intended application areas)
- 2Reasoning depth required (from simple logical inference to complex multi-step reasoning)
- 3Input modality support (text-only vs. multimodal capabilities)
- 4Performance variability across different contexts
These benchmarks collectively provide a comprehensive view of model capabilities, helping product leaders make informed decisions about model selection and identify areas requiring additional fine-tuning.
The careful selection of appropriate benchmarks is essential for meaningful evaluation that translates to real-world performance.
You learn more about Advanced Reasoning Benchmarks in Large Language Models. Here, we cover MMLU-Pro, GPQA, Diamond, and other Reasoning Benchmarks.
ARC-AGI and MMMU: Advanced reasoning frameworks
ARC-AGI (Abstraction and Reasoning Corpus) and MMMU (Massive Multi-Discipline Multimodal Understanding) represent significant advancements in evaluating large language models' reasoning capabilities.
ARC-AGI: Testing abstract reasoning
ARC-AGI, developed by François Chollet in 2019, measures intelligence through abstract reasoning rather than narrow skills or memorization. Unlike traditional benchmarks, ARC-AGI evaluates an AI's ability to recognize patterns, apply abstract concepts to new situations, and reason with minimal examples.

Source: ARC-AGI
The benchmark consists of visual puzzles requiring understanding of core knowledge concepts like object permanence, spatial relationships, and causality. Through 2025, it has become a critical standard for evaluating frontier AI models including Claude, GPT, and o3 systems.
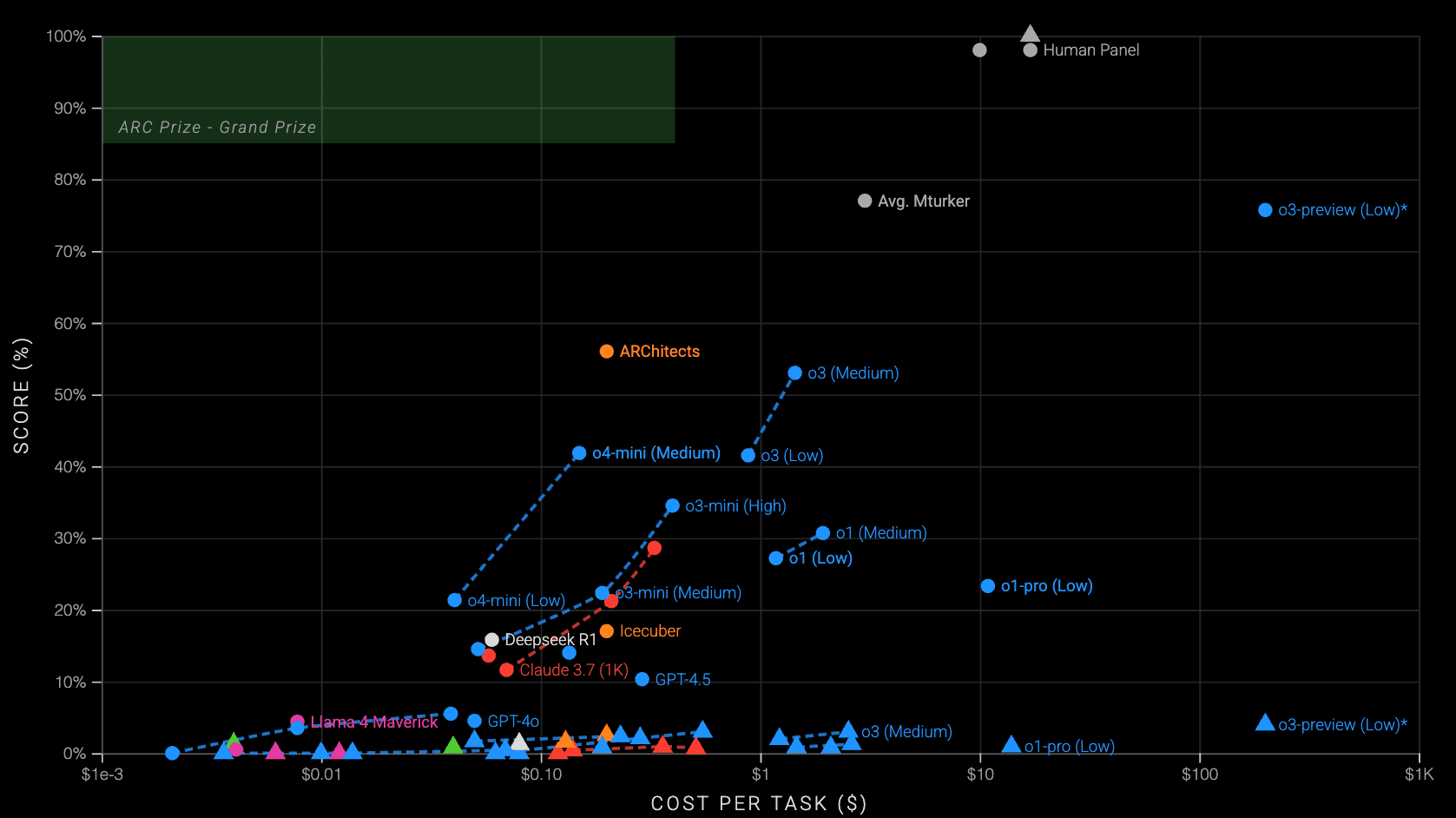
Graph showing how much LLMs still need to catch up and surpass Human performance in reasoning | Source: ARC-AGI Leaderboard
Key ARC-AGI Testing Areas:
- Few-shot learning capabilities
- Common-sense reasoning
- Pattern recognition
- Abstract concept application
- Generalization abilities
ARC-AGI specifically tests few-shot learning and common-sense reasoning capabilities. This makes it particularly valuable for assessing LLMs' potential for generalization and cognitive flexibility.
AI Systems Comparison in ARC-AGI dataset (till April 2025)
Recent leaderboards still highlight the gap between human-level abstract reasoning and even the most advanced AI systems.
The rigor and design of ARC-AGI continue to make it one of the most challenging and insightful benchmarks for evaluating true reasoning capabilities.
To gain a thorough understanding of the ARC-AGI benchmark, check out our blog here.
MMMU: Expert-level multimodal reasoning
MMMU tests models across diverse disciplines requiring both visual and textual understanding. It features complex problems from fields like medicine, science, engineering, and mathematics that assess expert-level reasoning abilities needed for AGI applications.
The benchmark comprises 11,500 carefully curated multimodal questions from college exams and textbooks, covering six core disciplines across 30 subjects and 183 subfields. Questions incorporate diverse image types including charts, diagrams, maps, and chemical structures.
MMMU Structure Breakdown:

MMMU focuses on advanced perception and domain-specific knowledge. Even top models like GPT-4V and Gemini Ultra achieve accuracies of only 56% and 59% respectively, indicating significant room for improvement.
The comprehensive nature of MMMU makes it exceptionally valuable for assessing a model's breadth of understanding across specialized domains.
Comparative model performance
Claude 3.7 Sonnet, Gemini 2.5 Pro, Grok 3, and Llama 4 have shown varied performance across these benchmarks. Models excel in different reasoning domains, with some showing strength in abstract pattern recognition while others perform better in domain-specific multimodal tasks.
Through early 2025, advancements in chain-of-thought prompting, test-time scaling, and other specialized reasoning techniques have become essential for optimal model performance across these challenging evaluation frameworks.
These comparative insights help product teams identify the specific strengths and weaknesses of each model for their particular use cases.
Implementation considerations
When integrating these benchmarks into development workflows, organizations should:
- 1Use ARC-AGI to evaluate general reasoning capabilities and cognitive flexibility
- 2Apply MMMU to assess domain-specific expertise and multimodal reasoning
- 3Combine multiple evaluation frameworks for comprehensive assessment
- 4Track performance over time to measure improvements
These frameworks provide critical insights into how models handle complex reasoning tasks, helping product teams make informed decisions about model selection and fine-tuning requirements.
Thoughtful implementation of these benchmark evaluations can significantly enhance product development and model selection processes.
I have covered a lot more about the MMMU LLM evaluation in the Multimodal Reasoning Benchmarks blog here.
Visual reasoning assessment: MathVista and multi-image frameworks
Visual reasoning benchmarks represent a significant evolution in evaluating AI systems' multimodal capabilities. These frameworks test how well models interpret and reason with visual information, a critical skill for real-world applications.
MathVista: Visual Mathematical Reasoning Evaluation

Overview of MathVista dataset | Source: MathVista: Evaluating Mathematical Reasoning of Foundation Models in Visual Contexts
MathVista focuses specifically on mathematical reasoning with visual inputs. It challenges models to interpret graphs, diagrams, and visual math problems. This benchmark has become crucial for assessing how well large language models process and understand mathematical concepts presented visually.
The dataset enables thorough evaluation of a model's ability to:
Visual Math Processing Capabilities:
- Extract numerical information from charts
- Interpret geometric visualizations
- Solve visual math problems with multiple steps
MathVista has revealed that even state-of-the-art models still struggle with complex visual reasoning compared to humans.
The insights gained from MathVista help identify specific areas where models need improvement in mathematical visual reasoning capabilities.
Multi-image reasoning frameworks
Beyond single-image assessment, multi-image frameworks test reasoning across multiple visual inputs. These benchmarks evaluate how models connect information between separate images and apply logical reasoning to draw conclusions.
Recent developments show significant progress in this area. The creation of MathV360K, a dataset with 40,000 high-quality images and 320,000 question-answer pairs, has substantially enhanced both breadth and depth of multimodal mathematical evaluation resources.
MathV360K Dataset Metrics:
These multi-image frameworks better simulate real-world scenarios where information must be integrated across different visual sources.
Performance improvements through specialized models
Research indicates that models fine-tuned specifically for visual mathematical reasoning show remarkable improvements. The Math-LLaVA model, based on LLaVA-1.5 and fine-tuned with MathV360K, achieved a 19-point performance increase on MathVista's minutest split.
Such specialized models demonstrate enhanced generalizability. Math-LLaVA shows substantial improvements on the MMMU benchmark as well.
These findings underscore the importance of dataset diversity and synthesis in advancing multimodal large language models' mathematical reasoning abilities. The gap between current models and human-level performance indicates significant room for further development in visual reasoning capabilities.
The specialized enhancement approach demonstrates promising pathways for targeted model improvement in visual reasoning tasks.
Read more about MathVista, and Multi-Image reasoning Frameworks here.
Document understanding evaluation: ChartQA, DocVQA, and TextVQA
Document understanding benchmarks evaluate multimodal LLMs' ability to comprehend and reason about visual content in documents. Each benchmark targets specific aspects of visual document comprehension with unique evaluation methodologies.
ChartQA
ChartQA tests models on interpreting charts and graphs, requiring both visual perception and numerical reasoning skills. Models must analyze visual data representations and perform calculations to answer questions about trends, comparisons, and relationships within charts. This benchmark reveals how well models can extract quantitative insights from graphical information.
The ability to accurately interpret charts and graphs represents a critical capability for business applications where data visualization is common.
DocVQA
DocVQA evaluates document understanding by requiring models to answer questions about both text and visual elements in documents. It focuses on the model's ability to locate and interpret information across different document components including text blocks, tables, and graphical elements. Models must demonstrate spatial awareness of document structure to succeed on this benchmark.
This benchmark is particularly valuable for assessing models intended for document processing, information extraction, and knowledge management applications.
Benchmark comparison:
Recent benchmark evolution
These benchmarks have evolved significantly through 2024-2025, with new metrics focusing on both accuracy and reasoning patterns. Current evaluation frameworks incorporate diverse metrics including:
Document Understanding Metrics:
- Accuracy and correctness of answers
- Quality of reasoning processes
- Hallucination rates in responses
- Consistency across multiple questions
The evolution of these metrics reflects a more nuanced understanding of what constitutes effective document comprehension by AI systems.
Performance insights
Recent research shows multimodal LLMs demonstrating improved performance but still struggling with complex visual reasoning compared to humans. While models excel at straightforward information extraction, they face challenges with:
Persistent Document Understanding Challenges:
- 1Multi-step numerical reasoning
- 2Understanding complex chart visualizations
- 3Integrating information across document sections
Human evaluation remains crucial for assessing nuanced understanding despite the development of automated metrics.
Current benchmarks increasingly focus on real-world applications, educational contexts, and cross-modal knowledge integration to better reflect practical document understanding needs.
These insights help product teams set realistic expectations and identify specific areas where human oversight may still be necessary.
You can read more about Image Understanding Benchmarks for LLM Evals here.
LLM performance analysis across reasoning benchmarks
Reasoning-based evaluations are essential for understanding how advanced language models handle complex tasks. Through April 2025, benchmarks like ARC-AGI, MMMU, MathVista, ChartQA, DocVQA, and TextVQA have provided critical insights into model capabilities.
Benchmark evolution and model advancements
Reasoning benchmarks have evolved significantly, with MMLU-Pro and GPQA Diamond setting higher standards than previous tests. Recent advancements show impressive gains in mathematical reasoning, as demonstrated in AIME 2025 performance metrics. Models including Gemini 2.5 Pro, DeepSeek-V3, o3, o4-mini, and Grok 3 compete for top positions on most leaderboards.
Chain-of-thought prompting has become essential for optimal model performance across these challenging frameworks.
The rapid evolution of both benchmarks and models highlights the dynamic nature of the AI landscape and the need for ongoing evaluation.
Architectural insights behind performance differences
The architectural differences between models largely explain their varying performance on reasoning tasks. Proprietary models like Grok-3 Sonnet, GPT4.5, o3, and o4-mini benefit from larger datasets and specialized optimizations, enabling them to outperform in knowledge-intensive tasks. Open-source alternatives like Llama 4 herd continue to close the gap, particularly in tool use and adaptability.
Models optimized for specific benchmarks may excel in those narrow tasks but show inconsistent performance across broader reasoning challenges.
Understanding these architectural differences provides context for performance variations and helps set appropriate expectations.
Cost-performance considerations
When selecting a model based on reasoning capabilities, cost-performance ratio is a critical factor. While Gemini 2.5, Grok-3, GPT4.5, o3, and o4-mini models deliver superior reasoning, their API costs can be prohibitive for large-scale applications. Meta Llama 4 offers a cost-effective alternative with competitive reasoning abilities for organizations with infrastructure to deploy open-source models.
Cost-Performance Decision Factors:
- 1API pricing structure (per token/request)
- 2Infrastructure requirements for deployment
- 3Training and fine-tuning expenses
- 4Performance trade-offs for specific tasks
- 5Long-term scalability considerations
Recent benchmark-optimized "speed running" models raise questions about real-world adaptability versus benchmark-specific tuning.
These cost-performance considerations are essential for sustainable AI implementation strategies, especially for organizations with budget constraints.
Learn more about LLM APIs here in this blog.
Future directions in reasoning evaluation
The future of reasoning evaluation will likely involve more dynamic benchmarks that better simulate real-world problem-solving scenarios. Multi-image reasoning frameworks and cross-modal evaluation increasingly challenge models to integrate information across different modalities, mirroring human cognitive processes.
As models continue to advance, the gap between human-level abstract reasoning and AI capabilities is narrowing, though significant challenges remain in areas requiring nuanced understanding and creative problem-solving.
These emerging directions suggest promising pathways for more comprehensive and realistic evaluation methodologies in the coming years.
Conclusion
Reasoning-based LLM evaluations have fundamentally transformed how product teams assess and select AI models. The comprehensive benchmarks spanning abstract reasoning (ARC-AGI), multimodal understanding (MMMU), visual mathematics (MathVista), and document comprehension provide a multidimensional view of model capabilities that simple accuracy metrics cannot capture.
Implementation requires strategic thinking: match benchmarks to your specific use cases, consider the trade-offs between specialized and generalized models, and recognize that benchmark performance doesn't always translate to real-world success. Models optimized for specific leaderboards may underperform in dynamic production environments.
Strategic Implementation Steps:
- 1Match benchmarks to specific use cases
- 2Balance specialized vs. generalized models
- 3Verify real-world performance beyond benchmark scores
- 4Develop systematic evaluation frameworks
- 5Account for organizational constraints and requirements
For product managers, these evaluations should inform roadmap decisions around model upgrades, feature prioritization, and capability gaps. AI engineers should look beyond headline scores to evaluate reasoning paths and failure modes. Leadership teams must balance the superior reasoning of proprietary models against the cost advantages and customization potential of open-source alternatives like Llama 4 and various Huggingface alternatives.
As benchmarks continue evolving toward more dynamic, real-world scenarios, the organizations that develop systematic evaluation frameworks aligned with their specific product needs will gain significant competitive advantages in the rapidly advancing LLM landscape.