
What Is Supervised, Unsupervised, and Reinforcement Learning?
Machine learning has three core paradigms. Each takes a different approach to learning from data.
Supervised learning works like having a teacher. It learns from labeled datasets where every input has a known output. Think spam detection—the model sees thousands of emails already marked as "spam" or "not spam." It identifies patterns. Then it can classify new emails.
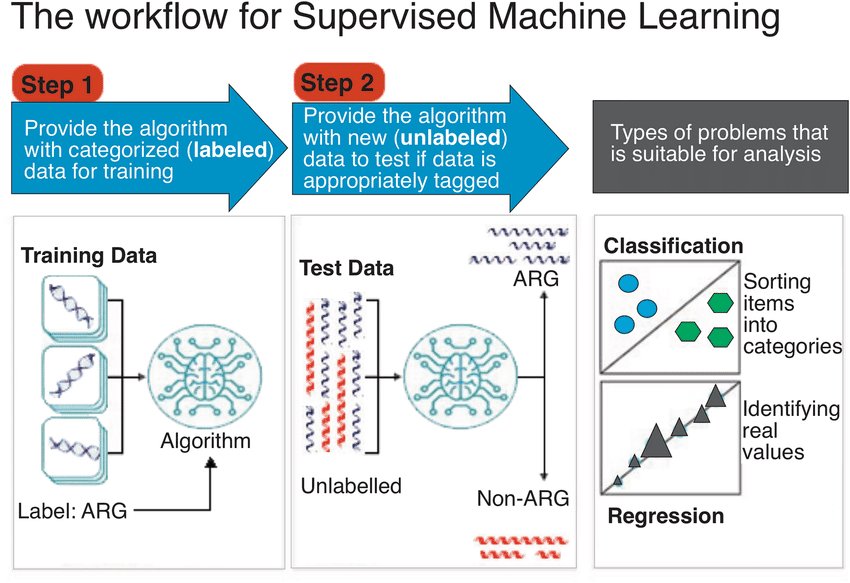
A general workflow of supervised learning. | Source: Alloghani et al. 2020
Unsupervised learning finds hidden patterns in unlabeled data. No teacher guides the process. The model discovers structures on its own. Customer segmentation exemplifies this. The algorithm groups customers by behavior without predefined categories.
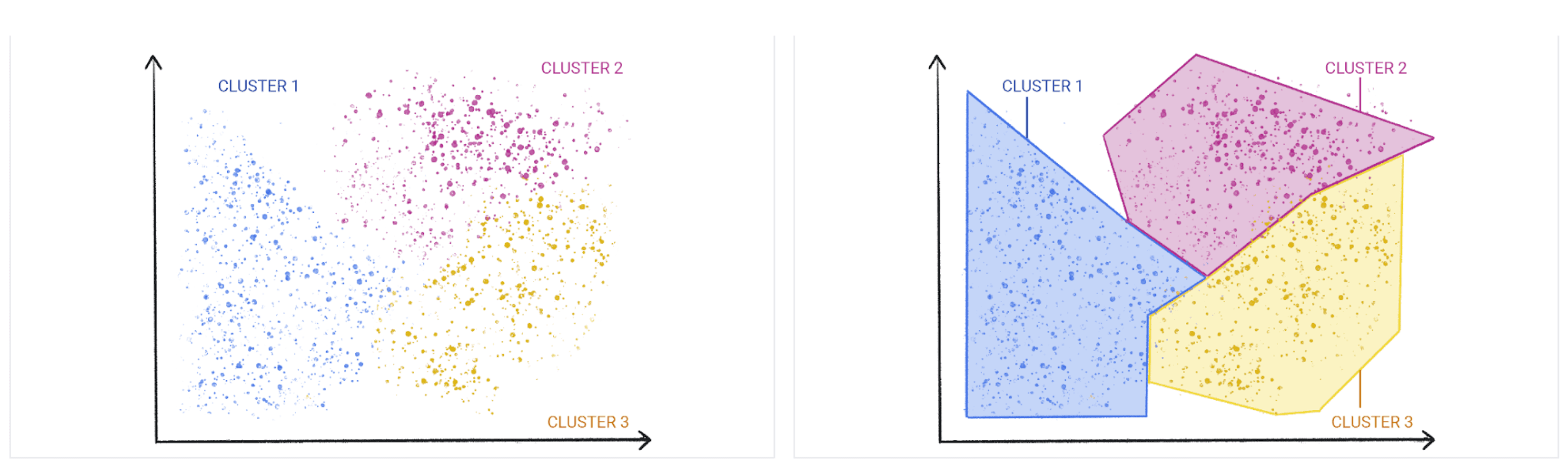
Unsupervised learning algorithms learn the underlying representation of the data or distribution and categorize or cluster them. | Source: What is Unsupervised Learning?
Reinforcement learning learns through trial and error. An agent takes actions in an environment. It receives rewards or penalties for each decision. Over time, it maximizes rewards. Game AI demonstrates this perfectly—learning optimal strategies through repeated play.
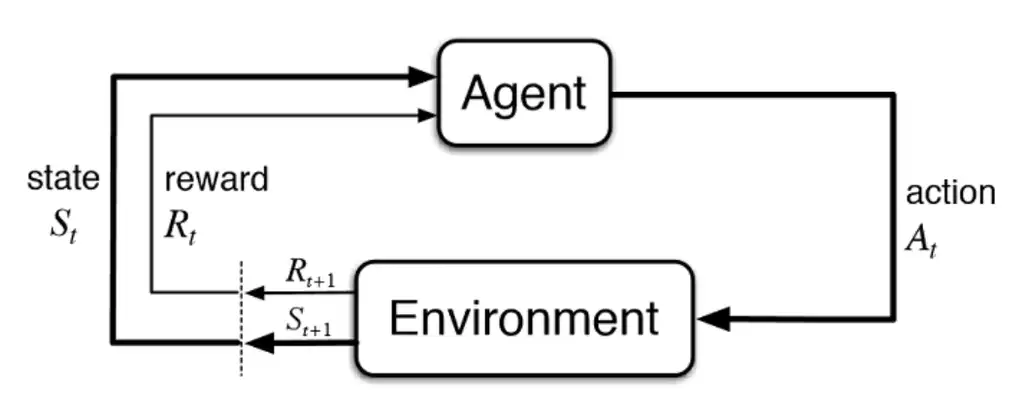
The interaction loop of an agent. | Source: Sutton, R. S. and Barto, A. G. Introduction to Reinforcement Learning
Key Differences: Supervised vs Unsupervised vs Reinforcement Learning
The difference between supervised and unsupervised learning and reinforcement learning lies in their data requirements and learning signals.
Reinforcement learning faces a unique exploration-exploitation trade-off. Agents must balance trying new actions versus repeating known successful ones. This makes RL ideal for dynamic environments like those in LLMs today, requiring adaptive strategies.
Reinforcement Learning vs Supervised & Unsupervised Learning
Reinforcement learning is neither supervised nor unsupervised. It forms a distinct third paradigm with unique characteristics. It solves sequential decision-making problems. It optimizes actions for maximum rewards through trial and error. Use it when you need adaptive behavior in dynamic environments.
Supervised learning tackles classification and regression problems. Use it when you have labeled examples—like medical diagnosis or fraud detection. Unsupervised learning discovers hidden patterns in unlabeled data. Apply it for customer segmentation or anomaly detection.
Examples clarify these distinctions:
- Supervised: Predicting house prices from historical sales data.
- Unsupervised: Grouping customers by purchasing behavior.
- Reinforcement: Training a robot to navigate obstacles.
Each paradigm serves different problem types and requires different data approaches.
Strengths, Challenges & Comparison
Each learning paradigm has distinct trade-offs that shape practical applications.
- Supervised learning delivers high accuracy but requires expensive labeled datasets.
- Unsupervised learning discovers hidden structures but outputs can lack interpretability.
- Reinforcement learning handles dynamic environments but faces sample inefficiency.
Choose supervised for well-defined prediction tasks with available labels. Pick unsupervised for exploration and pattern discovery. Select reinforcement for adaptive decision-making in dynamic settings.
Choosing or Combining the Best Approach
Modern applications increasingly blend paradigms rather than choosing just one. The difference between supervised and unsupervised learning and reinforcement learning becomes less relevant when combining approaches strategically.
Semi-supervised learning merges supervised and unsupervised techniques. It uses small amounts of labeled data alongside vast unlabeled datasets. This hybrid approach reduces labeling costs while maintaining performance. Companies like Google apply this for image recognition with limited labeled examples.
Reinforcement Learning from Human Feedback (RLHF) represents another breakthrough combination. Modern language models like GPT-4o, ‘o’ series, and Claude use RLHF to align with human preferences. The process trains reward models on human feedback, then fine-tunes models using reinforcement learning. This creates more helpful and harmless AI systems.
Consider your constraints when selecting approaches:
- Limited labels: Semi-supervised learning.
- Dynamic environments: Reinforcement learning.
- Human alignment: RLHF or Constitutional AI.
- Pattern discovery: Unsupervised learning.
The future belongs to hybrid methods that combine strengths while minimizing individual weaknesses.