
LLM tool calling transforms AI systems from text generators into action-oriented automation engines. By creating a structured bridge between language models and external APIs, developers can build systems that understand requests and execute real-world actions. This capability addresses fundamental limitations in base LLMs while opening new possibilities for product teams building the next generation of AI applications.
The technical foundation of tool calling leverages JSON schema definitions that specify function signatures, parameter types, and validation constraints. When properly implemented, this mechanism creates a reliable orchestration layer where the LLM determines when to invoke tools, generates structured parameter sets, and processes returned information - all without requiring extensive prompt engineering.
For product teams, tool calling solves critical barriers to practical AI implementation: knowledge cutoffs disappear with real-time data access, complex calculations become trivial through external processing, and domain-specific actions can be triggered through simple conversational interfaces. The result is AI that extends beyond content generation into meaningful automation.
This article covers:
- 1LLM architecture fundamentals and inherent limitations
- 2JSON schema design for robust tool implementations
- 3Provider-specific implementations (OpenAI, Anthropic, etc.)
- 4Framework integration with LangChain and LangGraph
- 5Parallel tool execution for performance optimization
- 6Best practices for production deployments
LLM architecture and capabilities
Large Language Models (LLMs) are built on transformer architecture, a revolutionary neural network design that processes text input through multiple specialized layers. This architecture allows LLMs to understand and generate human language with remarkable fluency.
Core architectural components
The foundation of modern LLMs is the transformer architecture, which replaced earlier sequence-to-sequence models. Transformers use self-attention mechanisms to weigh the significance of different words in relation to each other. This enables the model to capture contextual relationships between words regardless of their position in a sentence.
Each transformer model consists of:
- 1Tokenization layers that convert text into numerical representations
- 2Self-attention mechanisms that establish word relationships
- 3Processing layers that interpret these relationships
- 4Output layers that generate coherent text responses
Tokenization processes
Tokenization is the first step in LLM text processing. It breaks text into smaller units called tokens, which can represent words, subwords, or characters. The choice of tokenization strategy significantly impacts model performance and output quality.
Different tokenization methods create trade-offs between vocabulary size and representation efficiency. Models with larger vocabularies can represent more words directly but require more parameters.
Self-attention mechanisms
The self-attention component is what allows LLMs to understand context. This mechanism calculates relevance scores between all pairs of tokens in the input sequence. By doing this, the model can focus on important relationships regardless of distance between words.
Self-attention enables LLMs to:
- Resolve references like pronouns
- Understand long-range dependencies in text
- Capture semantic relationships between concepts
- Process input in parallel rather than sequentially
Parameter scaling effects
Modern LLMs contain billions of parameters, with larger models demonstrating enhanced reasoning capabilities. As parameter count increases, models show improved performance across various tasks following predictable scaling laws.
The relationship between model size and capabilities isn't simply linear. LLMs exhibit emergent abilities at certain scale thresholds—capabilities that weren't explicitly trained for but arise from increased parameter count.
Text generation approaches
LLMs generate text through various sampling techniques, each with distinct trade-offs:
- Greedy search always selects the most probable next token
- Beam search maintains multiple candidate sequences
- Temperature sampling introduces controlled randomness
- Nucleus sampling (p-sampling) balances creativity and coherence
These approaches affect the diversity, creativity, and predictability of generated text.
Inherent limitations
Despite their impressive capabilities, base LLMs have several inherent limitations:
- Knowledge cutoffs that restrict awareness of recent events
- Poor performance on complex arithmetic and logical reasoning
- Inability to access private or specialized data
- Tendency to hallucinate facts when uncertain
These limitations are often addressed through integration with external tools, retrieval augmentation, or fine-tuning with specialized knowledge.
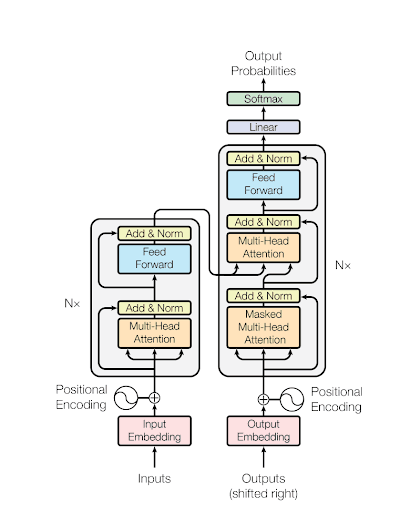
A visualization of the transformer architecture | Source: Attention is all you need
While understanding LLM architecture provides essential context, these inherent limitations highlight exactly why tool calling capabilities have become so crucial. Let's explore how tool calling addresses these constraints by connecting LLMs to external systems.
Tool calling fundamentals
Understanding the orchestration layer
Tool calling represents a major architectural shift in how LLMs interact with external systems. Rather than simply generating text, tool calling provides an orchestration layer that enables LLMs to integrate with deterministic APIs and functions. This capability transforms LLMs from isolated text generators into systems that can interact with databases, retrieve real-time data, or trigger specific actions.
JSON schema structure
The foundation of effective tool calling lies in properly defined JSON schemas. Each tool requires a clear name, description, and parameter structure. When an LLM decides a tool is appropriate for a task, it pauses text generation and outputs structured JSON-formatted parameters that follow the predefined schema. This structured approach ensures consistent and reliable LLM and external systems interactions.
Below is an example of OpenAI tool calling using a JSON schema structure.
Source: Function calling
Provider implementation differences
Different providers implement tool calling with notable variations. OpenAI offers tool calling through both ChatCompletions and Assistants APIs, supporting parallel execution of multiple tools. Anthropic handles tool responses within user roles rather than separate roles. LangChain provides a unified interface that abstracts these differences, allowing developers to work across providers consistently.
The tool calling workflow
The systematic workflow of tool calling follows a clear sequence:
- 1First, the LLM analyzes the user query to determine if a tool is needed. When required, it selects the appropriate tool and generates structured outputs following the schema definition.
- 2The system then executes the tool with these parameters and passes the results back to the LLM for response synthesis.
Applications beyond text generation
Tool calling powers complex AI agents to perform sophisticated automations based on context. For example, GitHub PR reviewers can analyze code changes and provide feedback by calling appropriate tools. This capability allows LLMs to extend beyond mere text responses into meaningful actions that solve real problems.
The foundation of reliable tool implementation rests on well-designed JSON schemas, which provide the structural blueprint for how LLMs interact with external systems. Let's examine how to create robust schema designs that ensure consistent tool behavior.
JSON schema design for robust tool implementation
In this section, we will cover the importance of JSON schema design for tool calling. Before we start discussing, go through the illustration of how function calling works.
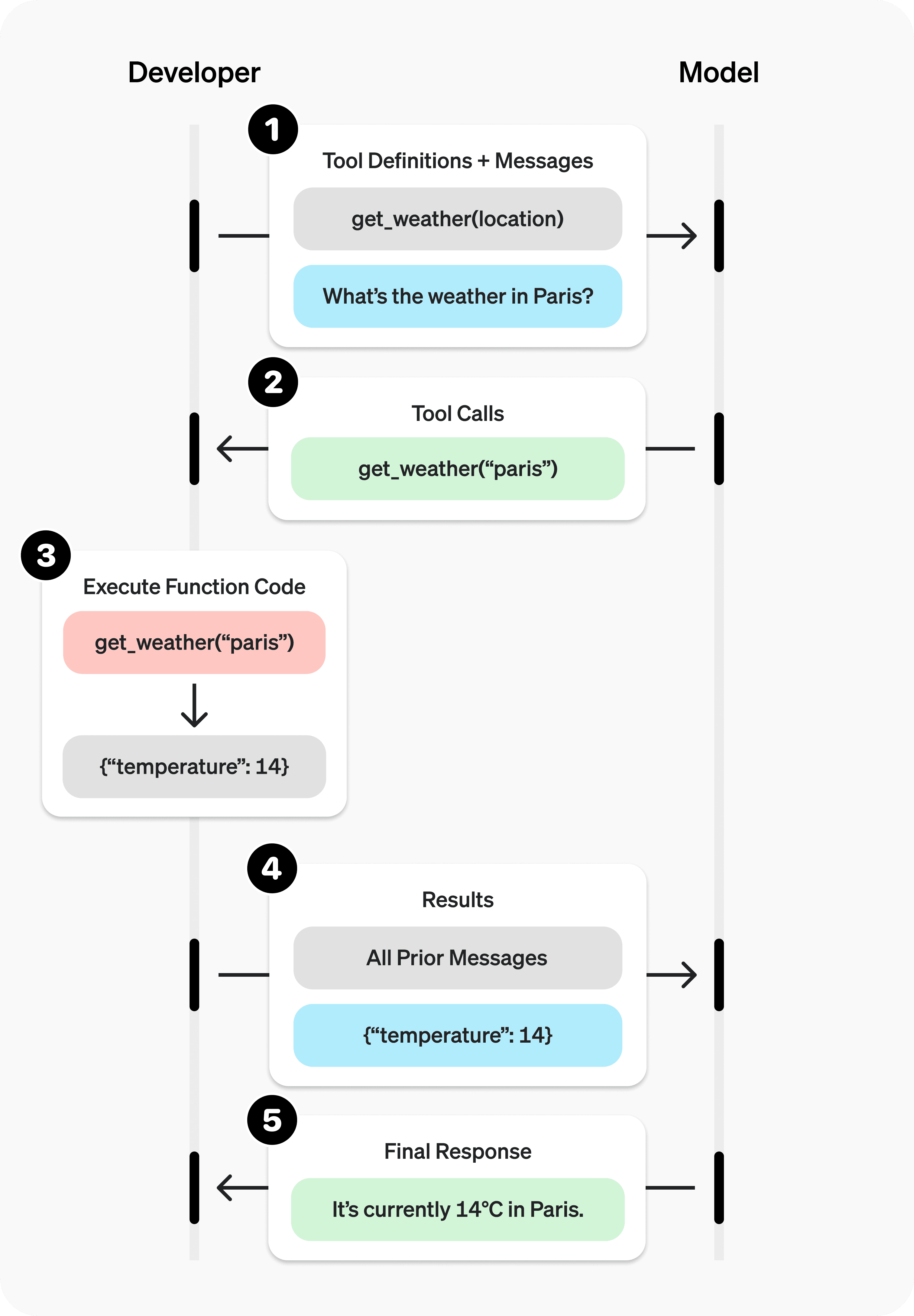
A comprehensive diagram illustrating how tool calling functions. | Source: Function calling
Keep in mind that the diagram above is derived from the code I mentioned earlier for tool calling.
Properties and type specifications
JSON Schema serves as a crucial foundation for reliable tool implementations in LLM systems. By defining clear properties, parameters, and data types, developers can ensure consistent data exchange between models and external tools. A well-structured schema explicitly specifies each field's type (string, number, boolean, array, object) and constraints, creating predictable interfaces for tool interaction.
Validation constraints
Implementing validation constraints within your schema prevents runtime errors and improves reliability. Essential constraints include required fields, minimum/maximum values for numeric data, string patterns using regular expressions, and properly structured nested objects. Setting additionalProperties: false prevents unexpected fields, reducing the risk of malformed data reaching your tools.
Parameter validation approaches
Effective parameter validation begins with clear descriptions for each field, guiding the LLM toward generating valid inputs. Using type-specific keywords (like minLength for strings or minimum for numbers) establishes boundaries for valid data. Production implementations should combine schema-level validation with client-side checks using libraries like Ajv (JavaScript) or jsonschema (Python) to catch potential errors before execution.
Schema versioning strategies
Maintaining backward compatibility through thoughtful schema versioning is essential for production environments. Effective strategies include additive-only changes (adding optional fields rather than removing existing ones), semantic versioning to communicate compatibility breaks, and schema evolution patterns that gracefully handle missing or deprecated fields. Consider implementing version identifiers within your schema to support multiple versions simultaneously during transition periods.
A single-sentence paragraph is sometimes the most powerful way to emphasize a critical point about schema design.
With a solid understanding of schema design principles established, let's explore how leading AI providers implement tool calling in their platforms, starting with OpenAI's approach to function calling and tool integration.
OpenAI tool calling implementation
Understanding the fundamentals
Tool calling enables LLMs to interact with external tools through structured outputs. This approach leverages an idiom that language models inherently understand for invoking external actions. The model generates JSON-formatted arguments for predefined tools, allowing developers to connect AI capabilities with external systems.
How tool calling works
At its core, a tool call consists of two main components: the function name and a structured set of arguments defined using JSONSchema. When implemented properly, the LLM can make a function call, read the results, and decide to retry if needed.
Implementation workflow
The standard implementation follows a four-step process:
- 1Define your tools with JSONSchema to specify function signatures
- 2Call the model with the user query and your function definitions
- 3Process the model’s response, executing any requested functions
- 4Return function results to the model for final response generation
A comprehensive diagram illustrating how tool calling functions. | Source: Function calling
Advantages of tool calling
Tool calling offers several significant benefits:
- 1
Structured Outputs
Arguments are always in JSON format with enforced parameter structure - 2
Token Efficiency
No need to waste tokens explaining format requirements - 3
Model Routing
Creates scalable architecture using modular prompts - 4
Safety Enhancement
Reduces vulnerability to prompt injection attacks
Parallel function calling
Advanced models like GPT-4 support parallel function calling, enabling multiple simultaneous tool calls in a single request. This capability:
- Improves efficiency for complex tasks requiring multiple operations
- Allows for better extraction of structured data
- Reduces overall token usage and latency
Error handling and security
Robust error handling is essential for production systems:
- Implement validation for function call arguments
- Create fallback mechanisms for failed calls
- Consider sending meaningful error messages back to the model
- Sanitize user inputs to prevent security vulnerabilities
Best practices for implementation
For optimal results with tool calling:
- Create detailed function descriptions and clear parameter schemas
- Keep functions simple and focused on specific tasks
- Test extensively with varied user inputs
- Monitor performance in production environments
- Implement proper authentication for external API calls
Tool calling transforms LLMs from simple text generators into powerful systems capable of taking action worldwide while maintaining developer control over execution.
While OpenAI’s implementation offers a robust approach to tool calling, other providers like Anthropic have developed their own unique implementations. Let's examine how Anthropic’s Claude models handle tool interactions and the specific considerations for working with this alternative framework.
Anthropic Claude tool use implementation
Similar to OpenAI tool calling, Anthropic also uses JSON schema format for tool calling. Below I have provided a Python example for tool calling using Anthropic.
Source: Tool use with Claude
Defining tools and model selection
Claude can interact with external client-side tools through a structured approach. To implement tool use, you define tools in the tools parameter of your API request. Each tool definition includes a name, description, and input parameters schema.
When choosing a model for tool use, consider your task requirements:
- Claude 3.7 Sonnet, Claude 3.5 Sonnet or Claude 3 Opus are better for complex tools and ambiguous queries
- Claude 3.5 Haiku or Claude 3 Haiku work well for straightforward tools
Implementation workflow
The tool use process follows a simple four-step workflow:
- 1Send a message to Claude with tools defined in your request
- 2Claude recognizes when to use a tool and returns a structured tool_use response
- 3Execute the tool with the provided arguments
- 4Return the tool execution results to Claude in a new message
For some workflows, steps 3 and 4 are optional, as Claude’s initial tool request might be sufficient.
Tool definition best practices
To increase the likelihood of Claude correctly using tools:
- Provide clear, unambiguous tool names
- Include detailed descriptions of when and how to use each tool
- Define parameter requirements precisely
- Follow the principle: if a human can understand the tool's purpose and usage, Claude likely can too
Chain of thought in tool use
Claude often displays its reasoning process when deciding which tools to use. Claude 3 Opus does this automatically with default settings, while Sonnet and Haiku models can be prompted to show their thinking with instructions like "Before answering, explain your reasoning step-by-step in tags."
This "thinking" provides valuable insight into Claude's decision-making process and can help debug unexpected behavior.
Controlling tool use behavior
You can control Claude's tool use behavior through parameters:
- Use tool_choice to force Claude to use specific tools
- Set disable_parallel_tool_use=true to prevent Claude from using multiple tools simultaneously
- Add explicit instructions in the user message for more nuanced control
With these implementation details, you can effectively leverage Claude's tool use capabilities to extend its functionality beyond standard text generation.
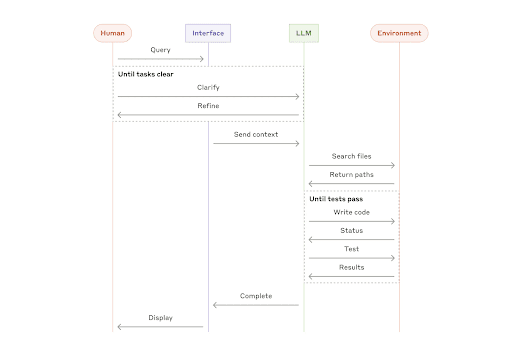
Claude’s high level overview of tool calling via agents for coding | Source: Building effective agents
Working with multiple LLM providers presents challenges in maintaining consistent implementation patterns. Fortunately, frameworks like LangChain offer standardized interfaces to streamline development across different platforms. Let's explore how these frameworks simplify tool integration.
Framework integration: LangChain and beyond
Standardizing tool calling across providers
LangChain implements standard interfaces for defining tools, passing them to LLMs, and representing tool calls. This framework effectively bridges differences between various LLM providers' tool calling implementations. While providers like OpenAI, Anthropic, Google, Mistral, and Cohere all support tool calling, they do so with different formats and conventions.
For instance, Anthropic returns tool calls as parsed structures within content blocks, while OpenAI separates tool calls into distinct parameters with JSON string arguments. LangChain resolves these differences through a unified interface.
Binding tools to models
The .bind_tools method connects tools to chat models that support tool calling features. This method receives a list of LangChain tool objects and binds them to the chat model in its expected format. Subsequent model invocations include tool schemas in calls to the LLM.
Chat models supporting tool calling implement this standardized method, allowing developers to switch between different LLM providers seamlessly. The framework's flexibility lets you define tools using Python functions, decorators, or Pydantic schemas.
Error handling architecture
Robust error handling is essential when working with tool calls. LangChain's architecture includes mechanisms for identifying and managing invalid tool calls. This can involve passing through underlying errors from third-party systems directly to users or using a separate AI agent to transform errors into user-friendly messages.
Tool calling optimization addresses unpredictable LLM behaviors when invoking tools. The framework includes techniques to ensure AI agents perform expected actions reliably.
Performance across implementations
The standardized tool calling interface enhances performance by allowing developers to easily switch between different LLM providers. Updates to both langchain_core and partner packages enable this flexibility.
LangGraph, an extension of LangChain, makes building agent and multi-agent flows simpler. Using the new tool_calls interface streamlines LangGraph agent construction, facilitating more complex implementations with less code.
While standard sequential tool execution works for many applications, complex workflows can benefit significantly from parallel execution techniques. Let's examine how parallel tool execution can dramatically improve performance and efficiency in AI applications.
Parallel tool execution techniques
Understanding LLMCompiler
LLMCompiler is a framework that optimizes orchestration of parallel function calling with LLMs. It automatically identifies which tasks can be performed in parallel and which are interdependent, addressing key limitations in traditional sequential execution models.
Traditional methods like ReAct require sequential reasoning and function calls, resulting in high latency, cost, and sometimes inaccurate behavior. LLMCompiler significantly improves these metrics by enabling tasks to execute concurrently.
Key components of parallel execution
LLMCompiler consists of three primary components:
- 1
LLM Planner
Identifies execution flow and generates a task sequence with dependencies - 2
Task Fetching Unit
Dispatches function calls in parallel - 3
Executor
Executes tasks and handles replanning when needed
This architecture mirrors best practices in software development: breaking complex problems into manageable pieces and implementing error handling through dynamic replanning.
Benefits over sequential execution
Sequential execution has several drawbacks that parallel execution addresses:
- Accuracy: Intermediate results can affect the LLM's flow in sequential models
- Speed: Parallel execution provides significant latency improvements (up to 3.7x)
- Cost efficiency: Reduced processing time leads to cost savings (up to 6.7x)
- Performance: Parallel execution can improve accuracy by up to 9%
Implementation in popular frameworks
Parallel tool calling capabilities are now supported in multiple frameworks:
- LangChain’s RunnableParallel
- LangGraph for complex agent workflows
- Native implementations in models from OpenAI, Anthropic, Cohere, and others
Each approach offers different concurrency management patterns, including rate limiting and error isolation mechanisms.
Performance considerations
When implementing parallel tool execution, consider:
- Task dependencies must be correctly identified to prevent errors
- Error handling becomes more complex in parallel execution
- Rate limiting may be necessary for external API calls
- Caching results can further improve performance
Parallel execution reduces latency and can outperform even the most optimized sequential implementations, as demonstrated by LLMCompiler’s 35% improvement over OpenAI’s parallel function calling.
Having explored all aspects of tool calling, from architecture to implementation and optimization, let's consolidate these insights into practical guidance for teams building tool-enabled AI applications.
Conclusion
Tool calling represents a paradigm shift in LLM application development, transforming models from passive text generators into active system orchestrators. By adequately implementing JSON schemas, validation constraints, and error handling, teams can build reliable AI systems that extend beyond the inherent limitations of base models.
The key technical takeaways include structured schema design as the foundation of reliability, the importance of clear parameter validation, and the significant performance gains possible through parallel execution. These elements combine to create systems that maintain deterministic behavior while leveraging the flexibility of natural language interfaces.
For product managers, tool calling enables feature expansion without extensive model retraining, allowing rapid iteration on product capabilities through modular tool additions. AI engineers should focus on robust error handling and schema versioning to maintain production stability. Startup leadership should recognize the strategic advantage of tool-enabled AI applications - they create defensible products by combining proprietary tools with commodity LLMs, significantly reducing implementation complexity while expanding capabilities beyond what competitors using vanilla LLMs can achieve.