
What Are Foundation Models?
To put it simply, the foundation model is a large neural network that is pretrained on a large amount of unlabeled data. These models are general AI models of multiple modalities like vision, language, speech, etc., trained and designed to perform a wide variety of AI-related tasks. Typically, these models contain billions or sometimes trillions of parameters. And they are trained using self-supervised learning. In self-supervised learning, the model sets up its own input as the target variable. The model essentially mask certain parts of the input and tries to predict it. These masked part may correspond to the missing word in a sentence or a missing patch in an image.
A general idea of where the foundation model sits in the overall AI product. | Source: Introducing Meta Llama 3: The most capable openly available LLM to date [April 18, 2024].
With such training techniques, the models extract patterns and meaningful representations of the training data. This means that they can be tamed to any downstream task with various pre-training phases.
Interestingly, these models are also addressed as Large X Models. “X” can be replaced with language, vision, and many others. Essentially, any large model can fit into the foundation model category if they are trained on a large amount of unlabeled data with self-supervised learning.
Some examples of foundation models are:
Open-source:
Private or closed-source.
In 2025 and onwards most of the foundation models are multimodal. Meaning, they can process multiple formats of information together. It is not like to have a separate model for text and video, but having a unified model. Today, these models are termed as large language model or LLM as language is found to be the common source of providing input – whether you are coding, analyzing data, generating or modifying image etc. As such, you will find that the models like GPTs and Claudes can process multiple information via prompts and speech in [and almost any languages].
Why do we need to pretrain new models? Because we can connect the old or current models to the internet and get fresh information. Right? The thing is, fresh training provides the model with a better worldview. It upgrades the model’s core skills and not just the memory. Connecting the search capabilities to the model means it can retrieve information and facts and then present them. Pretraining gives the models the ability to use those facts well.
Why do we need a foundation model?
Once the model is trained with the world’s knowledge, it contains the world model. Now, companies finetune these foundational model with their own domain-specific data and guardrails. This will make the finetuned model more aligned with company and it will also contain skills and general knowledge found from the world data.
Training Foundation Models
Training foundation models feels mysterious because the full recipe is rarely spelled out. In practice, training has two phases. First comes the pre-training phase. Here a raw architecture is trained on massive unlabeled text using self-supervised learning. The model learns patterns without human labels, predicts masked or next tokens, and builds general representations it can reuse later.
Recently, there has been an addition to the pre-training phase called the mid-training phase. In the mid-training phase the model is continued-trained on:
- More curated data and higher quality dataset. This reduces noisy signals.
- Lowered learning rate for reducing or eliminating gradient variance.
- Increased context window.
Essentially, mid-training phase allows the model to be more sharp, preparing it for reasoning capabilities with higher context window. This reduces pressure from post-training phase and increases accuracy and generalizability.
Second comes the post-training phase. This phase can be broken down into various sub-phases like,
- 1Instruct tuning, to follow instructions. Here the model is trained with supervised learning of input, output or instruction, response data. This is also called Supervised Fine-Tuning or SFT.
- 2Preference tuning, is all about aligning the models with human preferences. This is achieved by Reinforcement Learning with Human Feed or RLHF, Direct Preference Optimization or DPO, etc.
- 3Then we have reinforcement finetuning or RFT. It is similar to SFT but instead of training on input-output pairs you train it using a programmable grader. The grader evaluates every response that the model generates. The training algorithm then optimizes the model’s parameters during backpropagation such the high-scoring response becomes more likely than low-scoring ones.
Scaling Laws
Scaling laws answer a hard question: how to predict performance before spending millions. Scaling laws are empirical relationships showing how loss and accuracy change with model size, data volume, and compute. In practice, they let you forecast gains, pick the right scale, and avoid waste. To put simply, performance improves predictably as you increase specific factors under defined budgets, as shown in the original OpenAI study on power-law behavior.
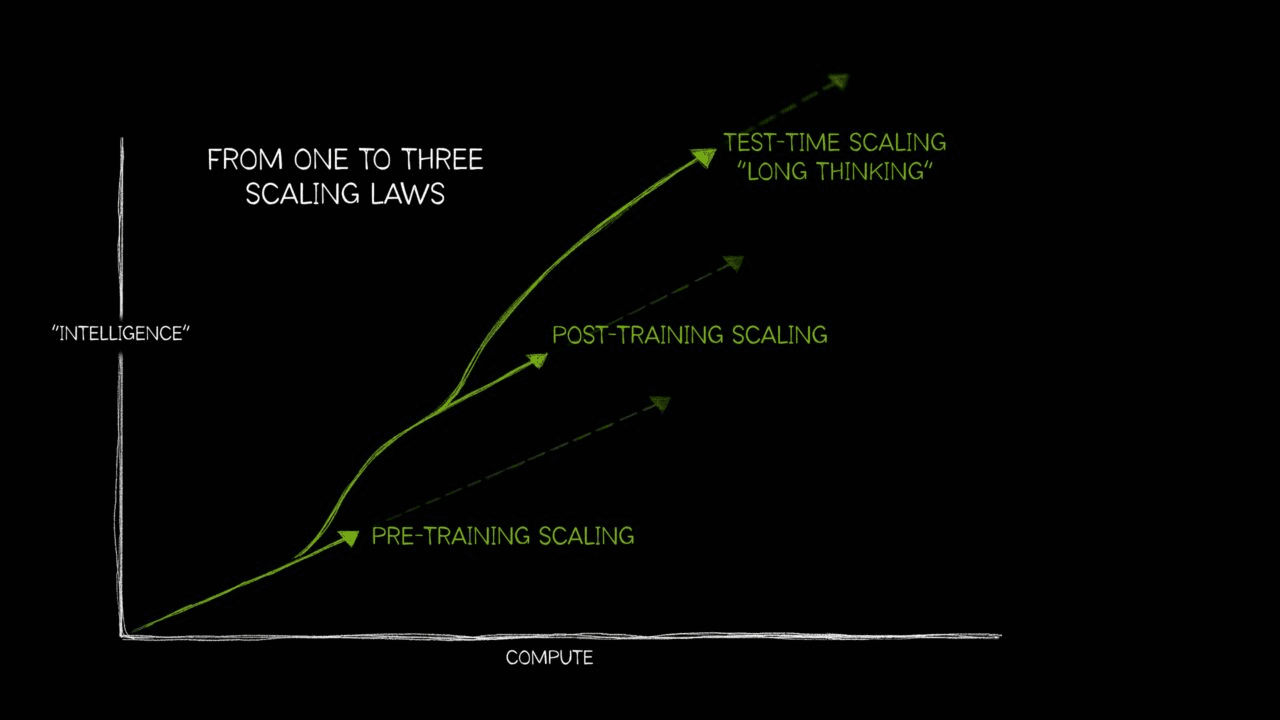
Three kinds of scaling now guide decisions:
- Pretraining scaling. The classic result; loss follows power laws with parameters, data, and compute; larger models are more sample-efficient at fixed budgets, per Kaplan et al.
- Post-training scaling. As enterprises adapt foundation models, cumulative compute for fine-tunes, pruning, distillation, and evaluations can total ~30× the foundation model’s original pretraining, according to NVIDIA’s 2025 guidance.
- Test-time scaling. Reasoning models like OpenAI’s o1 improve as you allocate more inference “thinking time.”Essentially, during inference, the model generate multiple paths for reasoning via chain-of-thoughts. It turns out that the more time and compute these models use the better is their responses.
Chinchilla changed the pretraining recipe. DeepMind showed that, for a fixed compute budget, balancing parameters and tokens is optimal. Roughly speaking, tokens should scale with model size rather than holding data constant. Chinchilla (70B) trained on 1.4T tokens and outperformed far larger models, establishing the data-optimal regime that many teams follow.

Chinchilla 5-shot accuracy compared to other models including the average human expert performance. | Source: Training Compute-Optimal Large Language Models
Why does this matter in planning? Scaling laws help teams forecast accuracy before expensive runs, split budgets between GPUs and data, decide whether to train bigger or longer, and justify infrastructure. Meta’s Llama 3 leaned into the Chinchilla view, pretraining on 15T tokens to unlock step-change performance across tasks.
Limits exist. Returns diminish at extreme scales, and leading researchers debate whether “just scaling” gets to general intelligence. Critics like Yann LeCun argue that richer objectives and world models are required, so leaders should pair scaling with better data, reasoning, and evaluation plans.
Prompt & Context Engineering: Maximizing Model Performance
The role of prompt and context engineering are playing a vital role in 2025. This is because most of the foundational models are [multimodal] LLMs. They operate on prompts. Prompts are crucial for getting aligned and structured response from the model. Good prompts matter more than model choice because structure reduces ambiguity. Meaning, clear instructions and relevant context beat clever wording every time. Most failures stem from unclear goals, missing constraints, or noisy inputs.
Prompt engineering is the practice of crafting inputs to get optimal results from language models using natural language rather than code, as outlined in the official OpenAI guide.
With model being trained on multiple larger compute clusters and with more data emergent quality tend to emerge. These quality sometimes tend to get transferred from other domains. For, instance a general model trained on coding data will perform better other reasoning tasks.
You do sometimes get surprising improvement in other domains. For example, when these large models improve at coding, that can actually improve their general reasoning
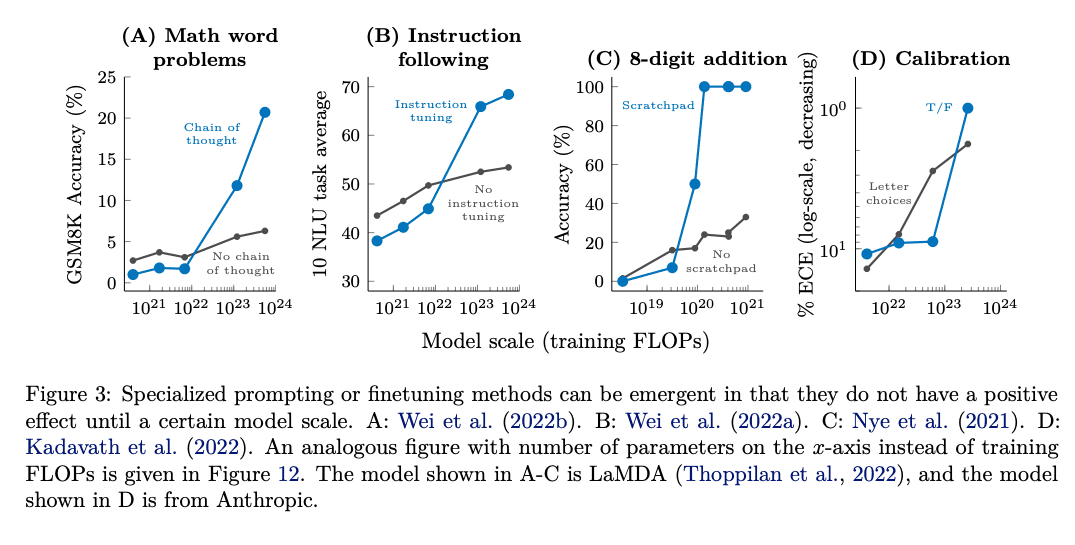
Scaling an LLM encourages emergent behaviour which produces better response from clear prompts. | Source: Emergent Abilities of Large Language Models
Core techniques that consistently work:
- Zero-shot prompting. Give direct instructions for simple tasks; for example, “Summarize this article in 100 words.”
- Few-shot prompting. Include two to five exemplars to lock format and tone; show three product descriptions, then request a fourth.
- Chain-of-thought. Ask the model to reason step by step (“Let’s think through this carefully”) to lift accuracy on logic tasks. Evidence from Wei et al. shows substantial gains on GSM8K.
Newer methods from 2024–2025:
- Self-consistency samples multiple solutions and selects the majority answer, boosting math and commonsense tasks by up to +17.9% on GSM8K.
- Emotional prompting adds stakes (“This is crucial for my career”) and has shown average 10.9% improvements across generative tasks.
- Meta-prompting uses task-agnostic scaffolds to orchestrate sub-tasks and outperformed baselines by 17% on composite benchmarks.
Context engineering manages what enters the model’s working memory.
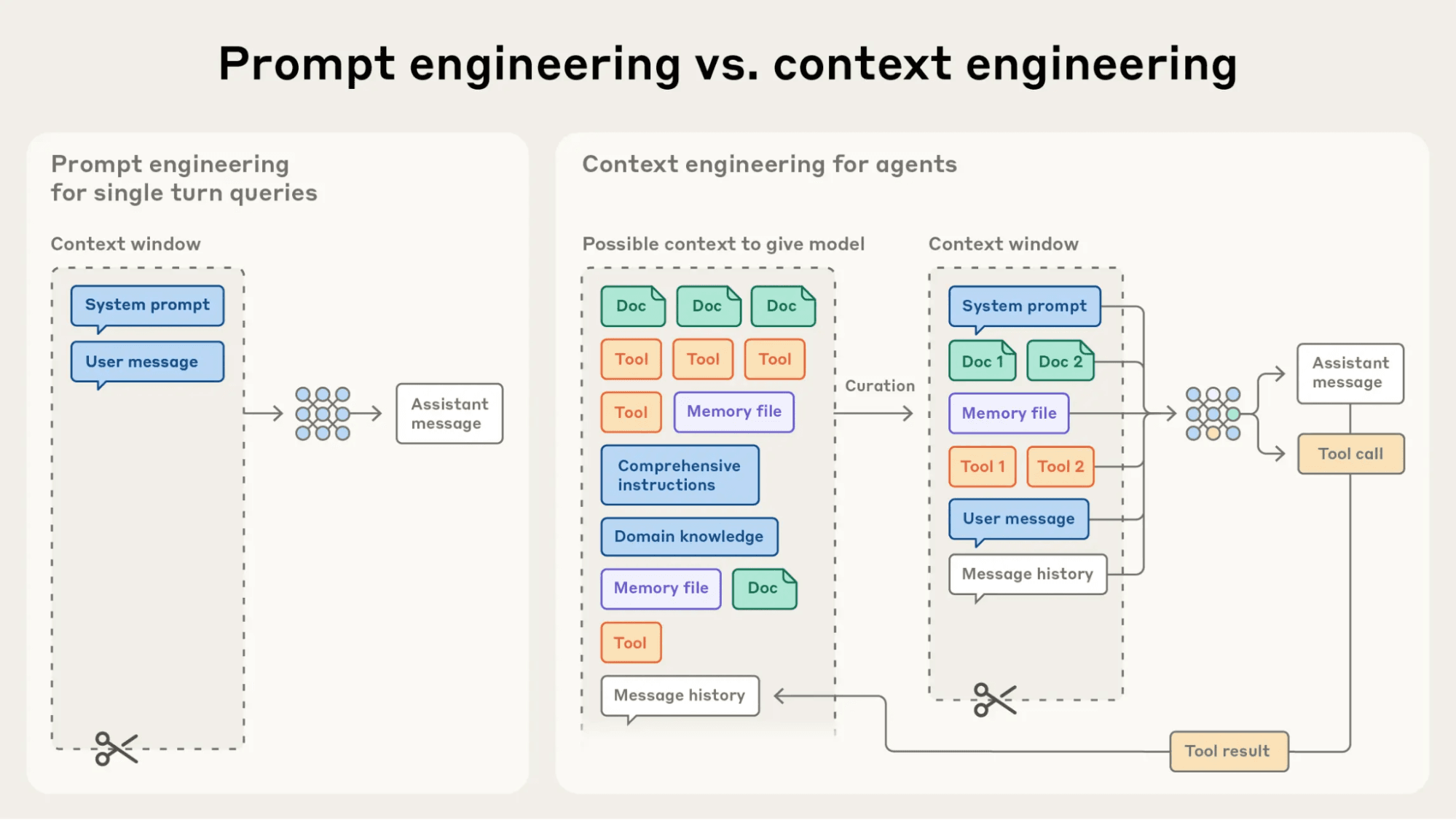
Difference between prompt engineering and context engineering. | Source: Effective context engineering for AI agents
Context windows have grown to 1 million tokens, with 2 million [Gemini 1.5 Pro] announced, yet bigger is not always better. Long-context studies show “lost in the middle” degradation around tens of thousands of tokens without careful placement.
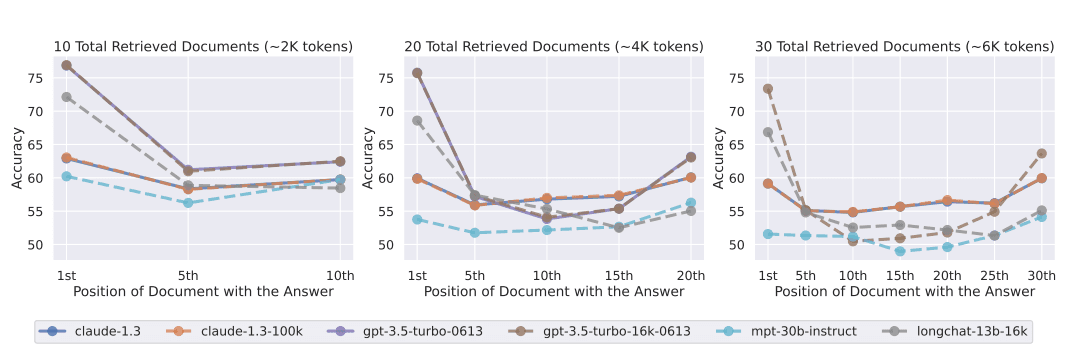
The retrieval strength of the models decreases as the context window increases [see the 10th position]. | Source: Lost in the Middle: How Language Models Use Long Contexts
Practical context strategies:
- Compaction. Summarize history and keep only decisive facts; prompt caching can cut costs up to 90% and latency up to 85% for long prompts.
- Progressive disclosure. Feed details only when needed to keep focus tight.
- Structured memory. Persist notes outside the window and retrieve selectively, as described in Anthropic’s context-engineering playbook.
Best practices: different models prefer different formats, so A/B test across versions, place critical instructions early, and iterate based on measured outcomes.
Adoption Strategies
Teams often ask whether to fine-tune, use RAG, or combine both. The answer depends on data freshness, required consistency, and available resources. No single path fits every workload.
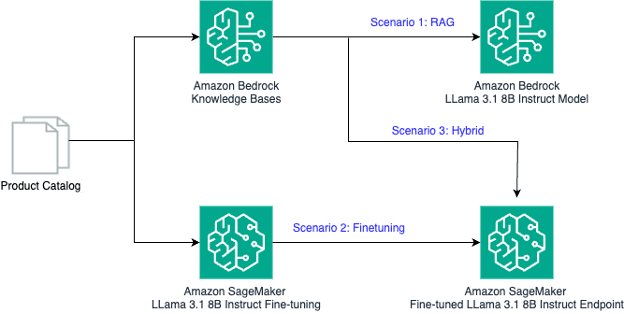
Source: Amazon Web Services, Inc.
Retrieval Augmented Generation
Use Retrieval-Augmented Generation (RAG) for dynamic knowledge, fine-tuning for specialized behavior, and a hybrid when you need both currency and consistency, as current cloud guidance emphasizes.
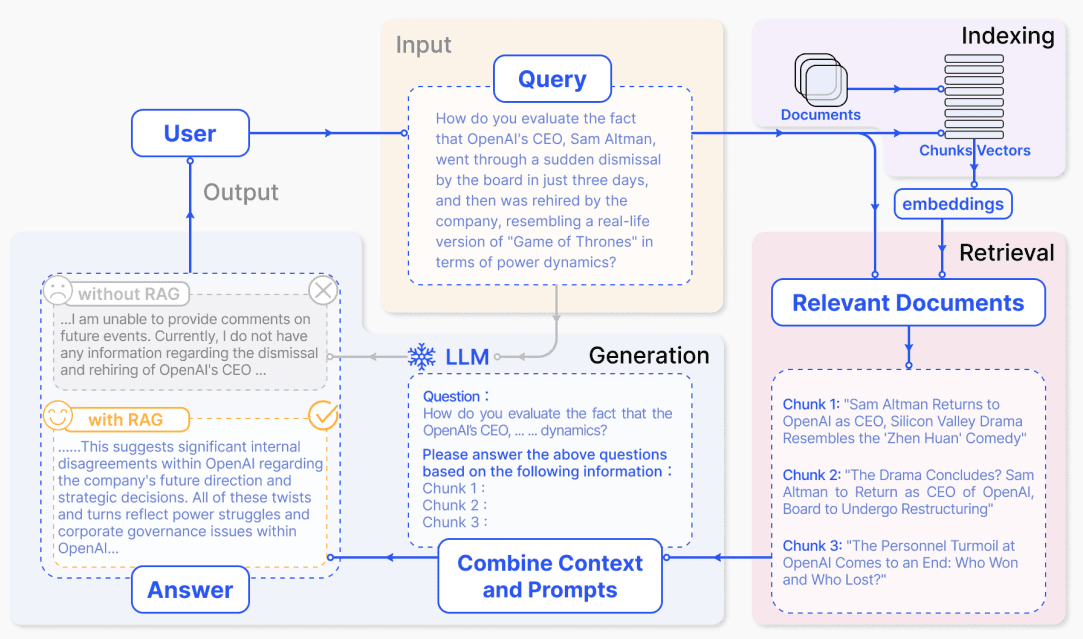
Overview of how RAG works – in four stages. Source: Retrieval-Augmented Generation for Large Language Models: A Survey.
RAG augments model responses with external facts through four steps:
- Document Ingestion: In the first step the document is loaded into a vector or search index. This is done by splitting the document then encoding them into vectors. Followed by storing them into vector database.
- Retrieval: Then, top-k documents are fetched from the vector DB that are most relevant to the prompt/query based on the similarity search. Similarity search is done using embeddings.
- Augmentation: The prompt and the retrieved docs are augmented or combined.
- Generation: The augmented prompt is to used to produce an answer grounded in sources. Ideal uses include fast-changing docs, product catalogs, and support knowledge; for example, a chatbot pulling the latest documentation with Pinecone.
Fine-tuning
Fine-tuning adapts a foundation or base model to domain data by continuing training on curated examples. Let’s you want to train an open-source model in your own domain-specific data. You can then download that model and then finetune it using your own training recipe.
However, finetuning these models are extremely expensive and it is almost impossible to train. But if you have a high-end GPU or GPU cluster(s) then finetuning will be easy. For a better perspective, if you want to train GPT-oss 120B model then these will be the requirements:
Obviously, these models cannot be trained in your laptops or Macbooks. But there ways in which you can shrink or quantize the model before finetuning them. Quantization will allow you to shrink the model more than half the size of the original model. This way you train them in your laptop locally.
Some quantization techniques are:
This suits consistent tone, heavy jargon, or low-latency tasks where retrieval would slow responses.
Hybrid Approaches
A hybrid approach fine-tunes for domain fluency and layers RAG for current information. Legal assistants, for instance, train on historical case law, then retrieve recent rulings and client files at answer time.
Decision framework:
- Choose RAG when data changes frequently, sources must be cited, or upfront spend must stay low.
- Choose fine-tuning when format and tone consistency matter or terminology is complex.
- Choose hybrid for enterprise workloads demanding both accuracy and freshness.
Costs differ. RAG adds vector search spend (for example, Pinecone minimums and Azure AI Search capacity), while fine-tuning concentrates cost during training but simplifies inference.
Tool Calling: Aligning Foundation Models with Products
There are certain information that time-based, like, weather, stock prices, current events, sports updates etc. Language models are limited to such data as they are trained on static data. As such, they cannot check weather or fetch prices on their own. They generate text from training data and have no system access.
Tool calling allows model by letting them invoke external functions and APIs. This turns text generators into action-taking agents.
Tool definition. Developers declare functions with names, descriptions, and JSON-Schema parameters, plus brief usage notes.
- Detection. The model inspects a user request and decides whether a tool is needed, then selects the function.
- Execution. The model emits structured JSON with function and arguments; the app executes and returns results.


- Integration. Returned data goes back to the model to compose the final answer.
Where does this matter today?
- E-commerce: Product search, stock checks, price updates, order status.
- Financial services: Real-time prices, portfolio analytics, transactions.
Pros and Cons
Foundation models mix real capability with real constraints. They deliver broad versatility but face reliability, cost, and transparency challenges. A balanced approach works best: map advantages to the specific use case, then layer safeguards for accuracy, privacy, and spend. Adoption surged because these models handle many tasks well, yet leaders still need guardrails and clear ROI targets.
Key advantages, with practical impact:
- Versatility. A single model handles translation, summarization, and coding, reducing per-task models, as Google Cloud’s overview notes.
- Transfer learning. Pretrained knowledge speeds new domains and lowers data needs, enabling faster deployments than training from scratch.
- Cost efficiency at scale. Providers cut prices in 2025 (for example, GPT-5 launched at lower rates), expanding access for startups.
- Rapid prototyping. Teams test ideas quickly and iterate on prompts, while 2025 pricing guides and caching discounts improve unit economics.
Technical challenges require clear mitigations:
- Hallucinations. Models can generate confident falsehoods; recent benchmarks quantify factuality gaps that demand verification systems.
- Knowledge cutoff. Models miss recent events without retrieval or tool calling, so RAG becomes essential for currency.
- Computational costs. Training and inference draw heavy energy and water; 2025 studies compare carbon and resource footprints across LLMs.
Operational risks must be addressed early:
- Interpretability. Black-box behavior complicates debugging and compliance in regulated sectors.
- Privacy and memorization. Research shows extractable training data and attribute inference risks, requiring governance and unlearning strategies.
- Bias and fairness. Societal biases in data can persist without audits and controls. NIST’s AI RMF provides practical guidance for risk management.
Cost management tips that move the needle:
- Monitor tokens, shorten prompts, and enable caching.
- Right-size models per task and evaluate open-source options.
- Tie spend to outcomes using 2025 pricing benchmarks and calculators.
Looking Forward: 2025 Trends
Three trends dominate 2025: agentic systems, efficiency gains, and domain specialization. Understanding these shifts helps teams prioritize skills and budgets. Foundation models are evolving from text generators into autonomous systems that plan, call tools, and deliver outcomes. Some examples that come to mind are: Grok-4 heavy, GPT-5 Pro, and also Claude Sonnet 4.5 and Opus 4.1.
Agentic Workflow of Grok-4 heavy. | Source: Grok 4
Key trends to watch:
- Agentic AI. Models increasingly use tools to execute multi-step workflows. Coding is emerging as the first breakout application; one market update estimates Claude captured 42% of developer share for code generation in mid-2025.
- Efficiency focus. Smaller, optimized models cut inference cost and enable edge deployment through quantization and pruning.
- Domain-specific models. Vertical foundation models for finance, healthcare, and legal report sizable accuracy lifts versus general models, and vendors increasingly position “sovereign AI” for regional needs.
Strategic implications:
- Invest in prompt and context engineering as durable skills.
- Prepare architectures for agentic workflows and tool calling.
- Track vertical model releases and sovereignty requirements by region.
Closing
Foundation models are the key to driving innovation and research. Start-up to Big Firms are relying on these models to get effective and productive results. The capabilities that the foundation model holds are truely magical. And although being general models, they have the capability to conform to the pattern of our workload and domain.